


浏览器解析html文档生成dom树的过程,以下是一段HTML代码,以此为例来分析解析HTML文档的原理
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<script src="script.js"></script>
<link rel="stylesheet" type="text/css" href="style.css">
<title></title>
</head>
<body>
<h1>HelloWorld</h1>
<div>
<div>
<p>picture:</p>
<img src="example.png"/>
</div>
<div>
<p>A paragraph of explanatory text...</p>
</div>
</div>
</body>
</html>浏览器解析HTML文档,在<head>中发现了<script>和<link>引入文件,于是向服务器请求文件,在请求和下载文件过程中将继续向下解析HTML,当引入文件下载完成后会通知浏览器回头来解析css和script文件。
如果浏览器在代码中发现一个<img>标签引用了一张图片,向服务器发出请求。此时浏览器同样不会等到图片下载完,而是继续渲染后面的代码;
现在进入正题,讲讲自己对解析HTML文档构建DOM树的理解:
此过程可分为两个主要模块构成,即
- 标签解析
- DOM树构建
1. 标签解析
这部分完成从HTML字符串中解析出标签的功能。主要使用标记化算法。
标记化算法的输入结果是HTML标记,使用状态机表示。状态机一共有4个状态:数据状态(Data)、标记打开状态(Tag open)、标记名称状态(Tag name)、关闭标记打开状态(Close tag open state)。
初始状态是数据状态。
当标记是处于数据状态时,
1)遇到字符<时,状态更改为“标记打开状态”:
a. 接收一个a-z字符会创建“起始标记”,状态更改为“标记名称状态”,并保持到接收>字符。此期间的字符串会形成一个新的标记名称。接收到>标记后,将当前的新标记发送给树构造器,状态改回“数据状态”
b. 接收下一个输入字符/时,会创建关闭标记打开状态,并更改为“标记名称状态”。直到接收>字符,将当前的新标记发送给树构造器,并改回“数据状态”。
2)遇到a-z字符时,会将每个字符创建成字符标记,并发送给树构造器。
2. DOM树构建
当标签解析器解析出标签后会发送到DOM树构建器,我们可以认为DOM树构建器主要有以下两部分组成:
- DOM树
- 一个存放标签名的栈
用如下代码演示生成DOM树的过程:
<html>
<body>
<h1>HelloWorld</h1>
<div>
<div>
<p>picture:</p>
<img src="example.png"/>
</div>
<div>
<p>A paragraph of explanatory text...</p>
</div>
</div>
</body>
</html><span><span class="tag"></span></span>首先树构建器接收到标签解析器发来的起始标签名后,会加入到栈中,图1是解析到<h1>标签的栈中压入的内容,共有<html><body><h1>三个标签,此时还未向DOM树中添加任何结点(图中黑色实线框代表开始标签,红色虚线框代表结束标签,结束标签不会入栈)。
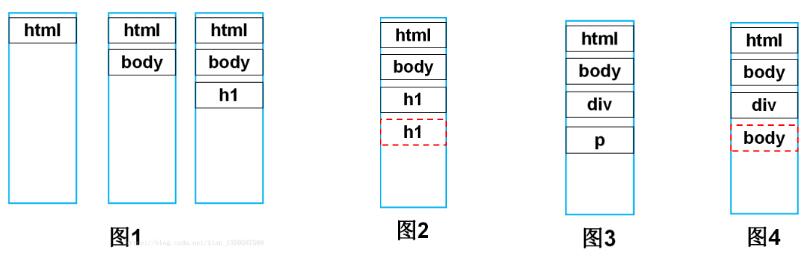
继续向下解析,接收到一个</h1>结束标签,此时查询栈顶元素,如果和传入的结束标签属于同种类型的p标签(如图2),则将栈顶元素弹出,向DOM树中加入此节点,然后继续向下解析(如图3)。
如果遇到的是没有封闭标签的元素如<img/>,则直接加入DOM树中即可,无需入栈。
依次向下解析,当栈为空,即<html>根节点也加入到DOM树中,DOM树构建完毕。
这里需要指出的是,当某个元素缺失结束标签时,假如上述代码中第一个<div>标签缺失了</div>结束标签,即:
<html>
<body>
<h1>HelloWorld</h1>
<div>
<div>
<p>picture:</p>
<img src="example.png"/>
</div>
<div>
<p>A paragraph of explanatory text...</p>
</div>
</body>
</html>那么,此时的栈如图4所示。即此时传来的结束标签是</body>,而栈顶元素是<div>,两者不是同一种标签,说明div缺少了结束标签,这种情况也将栈顶<div>元素弹出,加入到DOM树中。相当于给<div>补了一个</div>结束标签。
来源:https://blog.csdn.net/Alan_1550587588/article/details/80297765
本文内容仅供个人学习/研究/参考使用,不构成任何决策建议或专业指导。分享/转载时请标明原文来源,同时请勿将内容用于商业售卖、虚假宣传等非学习用途哦~感谢您的理解与支持!
全面理解虚拟DOM,实现虚拟DOM
DOM是很慢的,其元素非常庞大,页面的性能问题鲜有由JS引起的,大部分都是由DOM操作引起的。虚拟的DOM的核心思想是:对复杂的文档DOM结构,提供一种方便的工具,进行最小化地DOM操作。
原生js获取DOM对象的几种方法
javascript获取DOM对象的多种方法:通过id获取 、通过class获取、通过标签名获取、通过name属性获取、通过querySelector获取、通过querySelectorAll获取等
js实现DOM遍历_遍历dom树节点方法
遍历DOM节点常用一般用节点的 childNodes, firstChild, lastChild, nodeType, nodeName, nodeValue属性。在获取节点nodeValue时要注意,元素节点的子文本节点的nodeValue才是元素节点中文本的内容。
如何编写自己的虚拟DOM
要构建自己的虚拟DOM,需要知道两件事。你甚至不需要深入 React 的源代码或者深入任何其他虚拟DOM实现的源代码,因为它们是如此庞大和复杂——但实际上,虚拟DOM的主要部分只需不到50行代码。
归纳DOM事件中各种阻止方法
事件冒泡: 即事件开始时由最具体的元素(文档中嵌套层数最深的那个点)接收,事件捕获:不太具体的节点应该更早接收到事件,而最具体的节点应该最后接收到事件.与此同时,我们还需要了解dom事件绑定处理的几种方式:
关于DOM操作是异步的还是同步的相关理解
先列出我的理解,然后再从具体的例子中说明:DOM操作本身应该是同步的(当然,我说的是单纯的DOM操作,不考虑ajax请求后渲染等);DOM操作之后导致的渲染等是异步的(在DOM操作简单的情况下,是难以察觉的)
JavaScript DOM事件模型
早期由于浏览器厂商对于浏览器市场的争夺,各家浏览器厂商对同一功能的JavaScript的实现都不进相同,本节内容介绍JavaScript的DOM事件模型及事件处理程序的分类。
vuejs2.0如何获取dom元素自定义属性值
设置定义属性值 :data-value=.., 2.直接获取 3.通过this.$refs.***获取 1.目标DOM定义ref值: 2.通过 【this.$refs.***.属性名】 获取相关属性的值: this.$refs.*** 获取到对应的元素 ...
整理常见 DOM 操作
框架用多了,你还记得那些操作 DOM 的纯 JS 语法吗?看看这篇文章,来回顾一下~ 操作 className,addClass给元素增加 class,使用 classList 属性

浏览器中的JavaScript:文档对象模型与 DOM 操作
JavaScript 并没有那么糟糕。作为运行在浏览器中的脚本语言,它对于网页操作非常有用。在本文中,我们将看到可以用哪些手段来修改 HTML 文档和交互。文档对象模型是在浏览器中一切的基础。但它究竟是什么呢?
内容以共享、参考、研究为目的,不存在任何商业目的。其版权属原作者所有,如有侵权或违规,请与小编联系!情况属实本人将予以删除!