



webkit中样式相关类及类间关系
资料来源: 《webkit技术内幕》
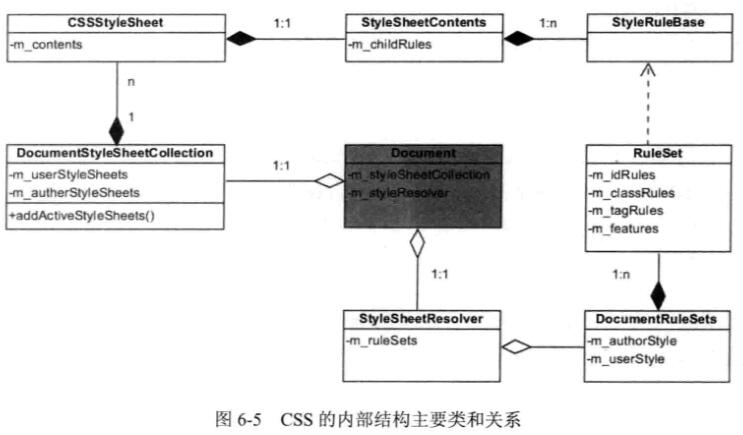
结构相关类:
1.StyleRuleBase类: 单个的样式规则(选择器+规则体)
2.StyleSheetContents类: 样式规则集,其成员-m_childRules是一个StyleRuleBase实例的列表,是1:n的数量关系
3.cssStyleSheet类: 成员-m_contents是一个StyleSheetContents实例,是1:1的数量关系
4.DocumentStyleSheetCollection类: 多种来源的CSSStyleSheet实例(用户样式表,网页作者样式表,默认样式表)的归类列表
5.Document类:
- 成员-m_styleSheetCollection: DocumentStyleSheetCollection的实例,数量关系1:1
- 成员-m_styleResover: 匹配css规则的相关类StyleSheetResover的实例,数量关系1:1
规则匹配处理相关类:
1.RuleSet类: 单个css样式表经css解释器之后的结果集,并且按照关键选择器的类型分类
- 成员-m_idRules: 该样式表中的id类型规则
- 成员-m_classRules: 该样式表中的class类型规则
- 成员-m_tagRules: 该样式表中的标签类型规则
- 成员-m_features: 该样式表中的其他特征类型规则
2.DocumentRuleSets类: 各种来源的样式表的合并(用户样式表/作者样式表/默认样式表)
- 成员-m_authorStyle: Ruleset对象的列表,代表作者样式表
- 成员-m_userStyle: Ruleset对象的列表,代表用户样式表
3.StyleSheetResover类: 规则匹配的主要负责类
- 成员-m_ruleSets: DocumentRuleSets类的实例
样式规则匹配
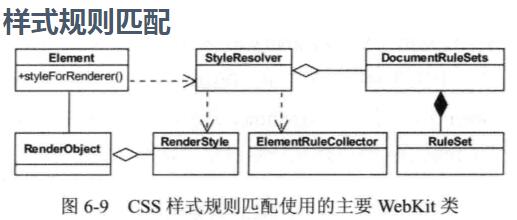
样式规则匹配大致过程
1.StyleResover类以ElementRuleCollector类为工具,为指定的元素匹配规则,并将匹配结果保存到RenderStyle对象中,RenderStyle对象由负责该元素渲染的RenderObject对象管理和使用
2.匹配的输入: StyleResover类中保存的css解释器的解释和分类完毕的样式规则
3.匹配用到的工具类: ElementRuleCollector类
4.被匹配对象: 指定html元素
5.匹配结果: 保存至RenderStyle对象并被RenderObject用于元素渲染
规则匹配的详细过程
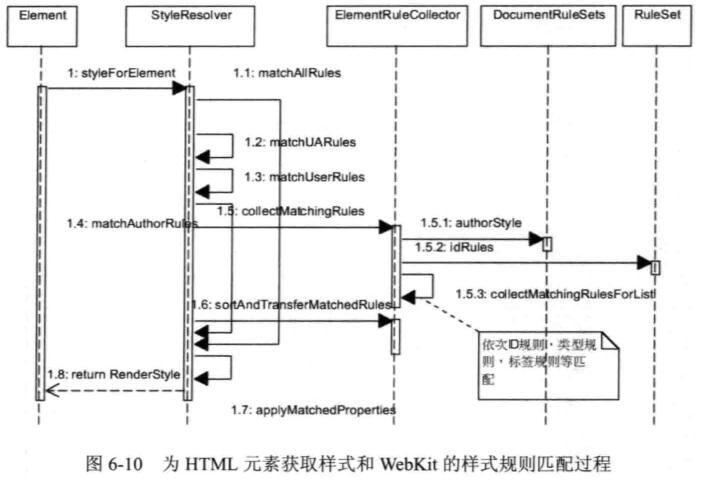
说明:
1.关键选择器: 样式规则的选择器字符串中的最右边选择器,它是样式规则在解释后分类的依据
2.匹配过程:
- matchAllRules: 匹配规则的最外层函数,包含匹配默认,用户和作者样式并收集和排序已匹配规则
- matchUARules: 匹配默认样式
- matchUserRules: 匹配用户样式
- matchAuthorRules: 匹配作者样式
3.作者样式匹配详细过程:(默认样式,用户样式的匹配类似)
匹配规则: 从右向左依次匹配选择器
前面我们已经知道解释之后的样式规则是分类存放在对象中的,而为当前元素匹配规则时,也是按id,class,tag,feature顺序依次匹配.
下面我们用伪代码来解释匹配的详细过程:(伪代码不是真正合理的和实际的代码)
1.重要参数
//参数e: 指代被匹配的元素
//重要的变量
var Result=[]; //用于保存完全匹配的结果集2.工具函数
function firstMatch(property,ruleSet){
//将元素的id/class/tag/feature与idRules/classRules/tagRules/featureRules匹配
//将匹配到的规则以数组返回,未匹配到返回空.
}
function getS(rule){
//获取单条rule规则的选择器数组
}
function Match(s,e){
//将选择器s与元素e匹配
//如果成功匹配则返回true,否则返回false
}
function leftMatch(rule,e){ //第一次匹配过后,用于处理结果集中单条规则的匹配的函数(调用Match函数)
var s = getS(rule); //获取单条规则的选择器数组
for(var i=s.length-1;i>=0;i--){ //从右到左依次将选择器与元素e匹配
var flag = Match(s[i],e);
if(!flag){ //一旦某次匹配失败,函数直接返回
return;
}
}
push(Result,rule); //仅当所有选择器都匹配成功,即完全匹配时,才将该条rule添加到Result
}
function ruleMatch(firstmatch,e){ //第一次匹配后的处理函数(调用leftMatch函数)
if(firstmatch为空){ //第一次匹配为空,直接返回
return;
}
for(var i=0;i<=firstMatch.length-1;i++){
leftMatch(firstMatch[i],e); //第一次匹配不为空,对每条匹配到的规则调用leftMatch
}
}3.id,class,tag,feature匹配的函数及调用顺序
//匹配idRules的函数
function idMatch(idRules,e){
var firstmatch = firstMatch(e.id,idRules);
ruleMatch(firstmatch,e);
}
//匹配classRules的函数
function classMatch(classRules,e){
var firstmatch = firstMatch(e.class,classRules);
ruleMatch(firstmatch,e);
}
//匹配tagRules的函数
function tagMatch(tagRules,e){
var firstmatch = firstMatch(e.tag,tagRules);
ruleMatch(firstmatch,e);
}
//匹配featureRules的函数
function featureMatch(featureRules,e){
var firstmatch = firstMatch(e.feature,featureRules);
ruleMatch(firstmatch,e);
}
//函数调用顺序
idMatch(idRules,e);
classMatch(classRules,e);
tagMatch(tagRules,e);
featureMatch(featureRules,e);4.说明
- firstMatch(property,ruleSet)函数: 代表按关键选择器的四种分类进行的第一次匹配,并返回匹配到的结果集(规则的数组)
- Match(s,e)函数: 代表第一次分类匹配后,对结果集内的单条规则中的单个选择器与元素的匹配
- leftMatch(rule,e)函数: 代表第一次分类匹配后,对结果集内的单条规则的所有选择器(从右至左)与元素的匹配
- ruleMatch(firstmatch,e)函数 : 代表第一次分类匹配后,完成接下来所有的匹配任务.
- 元素的内联样式是不经过上述匹配过程的,因为它本身就是专为该元素定义的样式.
权重(优先级)计算
1.选择器字符串的权重(specifishity)
(1)css中的权重模型(I-S-A-B-C)
其中:
I: 指代该规则是否为!important规则
S: 指代该规则是否为内联样式规则
A-B-C: 为内核定义的三类简单选择器
基础部分: A-B-C模型(以webkit为例)
浏览器内核用一个32位二进制数来表示某css规则的权重值,其基础部分的A-B-C模型是指权重计算的三类增量.
- A: id选择器,增量为0x10000
- B: 类选择器,属性选择器和伪类选择器,增量为0x100
- C: 元素选择器和伪元素选择器,增量为1
说明:
- 上述三类增量的定义位于webkit内核中的CSSSelector.h头文件中
- 关于I和S,取值只有0和1,不属于增量模型,我们可以假定为该32位二进制数的最高位和次高位.
- **通用选择器(*)**,选择器组合符(+,>,~,空格,||)不影响权重值
- 取反伪类 :not()
- 在selector level 3标准(现行标准)中,:not()只接受一个简单选择器为参数,其本身不影响权重,其权重为其参数的权重
- 在selector level 4草案中, :not()接受一个选择器列表为参数,其本身不影响权重,其权重为选择器列表中权重最高的参数的权重.
2.CSS规则权重的计算:
- 选择器字符串中:
- 每出现一个C类简单选择器,权重值增1
- 每出现一个B类简单选择器,权重值增0x100
- 每出现一个A类简单选择器,权重值增0x10000
- 如果是元素的内联规则,次高位置1(笔者假设)
- 如果是!important规则,最高位置1(笔者假设)
- 意义: 高权重值的规则将覆盖低权重规则中的相同属性的值(也就是:设置相同属性的值,高权重有效,地权重失效)
2.涉及到作者样式,用户样式,默认样式三种样式来源时的权重规则
- 作者样式/网页作者样式(author style sheets): 网页作者规定的样式(网页样式的主要来源)
- 用户样式(user style sheets): 用户自定义的个性样式(各大浏览器都在自行废除中)
- 默认样式/浏览器样式(user agent style sheet): 用户代理的默认样式(一般用于前两种都未涉及到的元素的样式)
一般,网页开发者和大多数用户考虑到的只有作者样式表和默认样式表(例如:用选择器*去掉默认样式中的元素margin和padding),而默认样式表中不含任何内联样式和!important样式.但是如果我们考虑上用户样式,权重规则可能会有一点不和谐的地方:(优先级从大到小)
用户样式!important规则 > 作者样式!important规则 > 内联样式 > 作者样式普通规则 > 用户样式普通规则
上面的优先级链中不包含内联!important规则,是因为一般的!important规则的目的就是为了以外部样式覆盖内联样式.
可见, 在普通规则和!important规则上, 两种样式表的权重情况是不同的.
- 一般规则: 作者样式 优先于 用户样式
- !important规则: 用户样式 优先于 作者样式
可能正是这样的不和谐,才使得各大浏览器都在逐渐废除用户样式吧.但是用户样式的实现可以借助浏览器插件间接实现,不过那又是另外一个故事了.
原文地址:https://www.cnblogs.com/peterzhangsnail/p/11053115.html
本文内容仅供个人学习/研究/参考使用,不构成任何决策建议或专业指导。分享/转载时请标明原文来源,同时请勿将内容用于商业售卖、虚假宣传等非学习用途哦~感谢您的理解与支持!
如何打造一个高权重的网站?
拥有一个高权重的网站,相信是各位站长一直以来的梦想。每天看着别人高权重、多流量的网站暗自羡慕,自己在想总有一天我也会做到一天10万IP,但想象归想象
css权重
通过以上实例,我们了解到了,简单好用的!important在一些场景里也是不好用的,尤其是当你随手拿来一个库使用的时候,你了解不到它内部的权重分布,所以样式操作起来也不能够得心应手。
JS简单实现:根据奖品权重计算中奖概率实现抽奖的方法
本文主要介绍:使用 JS 根据奖品权重计算中奖概率实现抽奖的方法。奖项权重:[1, 5, 20, 74]。奖项权重主要用来表征各奖项的中奖几率,这里奖项权重数组的和值为100(=1+5+20+74),其中1表示一等奖的中奖概率为1%;

css权重如何计算的?
CSS权重是由四个数值决定,第一等:内联样式,如:,权值为1000.(该方法会造成css难以管理,所以不推荐使用)第二等:ID选择器,如:#header,权值为0100.第三等:类、伪类、属性选择器如:.bar, 权值为0010.
css的权重
行内样式总会覆盖外部样式表的任何样式(除了!important),单独使用一个选择器的时候,不能跨等级使css规则生效,如果两个权重不同的选择器作用在同一元素上,权重值高的css规则生效
内容以共享、参考、研究为目的,不存在任何商业目的。其版权属原作者所有,如有侵权或违规,请与小编联系!情况属实本人将予以删除!