


Trie树(来自单词retrieval),又称前缀字,单词查找树,字典树,是一种树形结构,是一种哈希树的变种,是一种用于快速检索的多叉树结构。
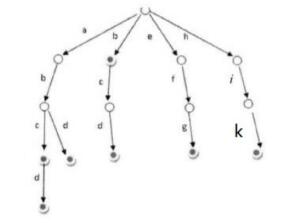
字典树是处理字符串常见的一种树形数据结构,其优点是利用字符串的公共前缀来节约存储空间,比如加入‘abc’,‘abcd’,‘abd’,‘bcd’,‘efg’,‘hik’之后,其结构应该如下图所示:
假设我有一个题目,要求设计一个存储至少500W量级英文单词的数据结构,需要满足下面两个需求:
1.当有新的单词加入时,需要判断是否在已经存储的单词中,如果不存在则直接插入
2.来了一个单词的前缀,统计一下存储的单词中有多少个单词前缀是和该单词前缀相同
下面我们开始来实现这个数据结构:
//字典树
var triNode = function(key){
this.key = key;
this.son = [];
this.isWord = false;//用于单词标记
}
var tree = function(){
this.root = new triNode(null);
}
tree.prototype={
insertData:function(stringData){
//用于外部调用插入,目的是从根节点开始插入
this.insert(stringData,this.root)
},
insert:function(stringData,node){
//用于内部自身递归调用,层层判断是否存在或是否要插入
if(stringData==''){
//字符串为空,直接返回结束
return;
}
//获取子节点
var son = this.getSon(node);
var haveData = null;
//声明一个变量用来存储字符串第一个字符和子节点相同的节点,方便后续节点递归遍历
for(var i in son){
if(son[i].key==stringData[0]){
haveData = son[i]
}
}
if(haveData){
if(stringData.length==1){
haveData.isWord = true;
}
//havaData存在说明在子节点找到了,然后进行深入节点查找
this.insert(stringData.substring(1),haveData)
}else{
if(son.length==0){
//如果子节点为空,则直接插入
var node = new triNode(stringData[0]);
son.push(node);
if(stringData.length==1){
node.isWord = true;
}
//插入完毕后将后续字符串继续插入
this.insert(stringData.substring(1),node);
}else{
var node = new triNode(stringData[0]);
//将子节点的key进行排序插入,方便后续进行二分法查找,加快查找效率
var vlPosition = 0;
for(var j in son){
if(son[j].key<stringData[0]){
vlPosition++;
}
}
if(stringData.length==1){
node.isWord = true;
}
//子节点插入
son.splice(vlPosition,0,node);
//插入完毕后将后续字符串继续插入
this.insert(stringData.substring(1),node);
}
}
},
justContentData:function(stringData){
if(stringData==''){
return 0
}else{
return this.justContent(stringData,this.root);
}
},
justContent:function(stringData,node){
if(stringData==''){
//字符串为空,直接返回结束
return 1;
}
var son = this.getSon(node);
var havaData = null;
for(var i in son){
if(son[i].key==stringData[0]){
havaData = son[i];
}
}
if(havaData){
return this.justContent(stringData.substring(1),havaData)
}else{
return 0
}
},
countBeforeData:function(stringData){
if(stringData==''){
return 0;
}
var node = this.searchBeforeNode(stringData,this.root);
if(!node){
return 0;
}
return this.countBefore(node,0);
},
searchBeforeNode:function(stringData,node){
if(stringData==''){
//字符串为空,直接返回结束
return node;
}
var son = this.getSon(node);
var havaData = null;
for(var i in son){
if(son[i].key==stringData[0]){
havaData = son[i];
}
}
if(havaData){
return this.searchBeforeNode(stringData.substring(1),havaData)
}else{
return null
}
},
countBefore:function(node,num){
if(node.isWord){
num++;
}
var son = this.getSon(node);
var havaData = null;
for(var i in son){
num=this.countBefore(son[i],num);
}
return num;
},
getSon:function(node){
//获取子节点
return node.son;
}
}
var msd = new tree()
//插入数据
msd.insertData("hello");
msd.insertData("helo");
msd.insertData("healo");
msd.insertData("haslo");
//前缀数量
msd.countBeforeData("ha");以上便是完整的一个解决上述问题的代码。字典树的一个常用场景有代码补全,输入框单词提示等。
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
Trie树也有它的缺点, 假定我们只对字母与数字进行处理,那么每个节点至少有52+10个子节点。为了节省内存,我们可以用链表或数组。在JS中我们直接用数组,因为JS的数组是动态的,自带优化。
来自:https://www.oecom.cn/js-use-trie/
本文内容仅供个人学习/研究/参考使用,不构成任何决策建议或专业指导。分享/转载时请标明原文来源,同时请勿将内容用于商业售卖、虚假宣传等非学习用途哦~感谢您的理解与支持!
js洗牌算法:javascript数组随机打乱顺序的实现方法
有一个数组,我们需要通过js对数组的元素进行随机排序,然后输出,这其实就是洗牌算法,首页需要从元素中随机取一个和第一元进行交换,然后依次类推,直到最后一个元素。
程序员必须知道的10大基础实用算法及其讲解
程序员必须知道的10大算法:快速排序算法、堆排序算法、归并排序、二分查找算法、BFPRT(线性查找算法)、DFS(深度优先搜索)、BFS(广度优先搜索)、Dijkstra算法、动态规划算法、朴素贝叶斯分类算法

js从数组取出 连续的 数字_实现一维数组中连续数字分成几个连续的数字数组
使用原生js将一维数组中,包含连续的数字分成一个二维数组,这篇文章分2种情况介绍如何实现?1、过滤单个数字;2、包含单个数字。
原生Js获取数组中最长的连续数字序列的方法
给定一个无序的整数序列, 找最长的连续数字序列。例如:给定[100, 4, 200, 1, 3, 2],最长的连续数字序列是[1, 2, 3, 4]。此方法不会改变传入的数组,会返回一个包含最大序列的新数组。
Tracking.js_ js人脸识别前端代码/算法框架
racking.js 是一个独立的JavaScript库,实现多人同时检测人脸并将区域限定范围内的人脸标识出来,并保存为图片格式,跟踪的数据既可以是颜色,也可以是人,也就是说我们可以通过检测到某特定颜色,或者检测一个人体/脸的出现与移动,来触发JavaScript 事件。
JS常见算法题目
JS常见算法题目:xiaoshuo-ss-sfff-fe 变为驼峰xiaoshuoSsSfffFe、数组去重、统计字符串中出现最多的字母、字符串反序、深拷贝、合并多个有序数组、约瑟夫环问题

RSA算法详解
这篇文章主要是针对一种最常见的非对称加密算法——RSA算法进行讲解。其实也就是对私钥和公钥产生的一种方式进行描述,RSA算法的核心就是欧拉定理,根据它我们才能得到私钥,从而保证整个通信的安全。
PageRank算法的定义与来源、以及PageRank算法原理
PageRank,网页排名,又称网页级别、Google左侧排名或佩奇排名,是一种由 根据网页之间相互的超链接计算的技术,而作为网页排名的要素之一,以Google公司创办人拉里·佩奇(Larry Page)之姓来命名。
js算法_js判断一个字符串是否是回文字符串
什么是回文字符串?即字符串从前往后读和从后往前读字符顺序是一致的。例如:字符串aba,从前往后读是a-b-a;从后往前读也是a-b-a
js之反转整数算法
将一个整数中的数字进行颠倒,当颠倒后的整数溢出时,返回 0 ;当尾数为0时候需要进行舍去。解法:转字符串 再转数组进行操作,看到有人用四则运算+遍历反转整数。
内容以共享、参考、研究为目的,不存在任何商业目的。其版权属原作者所有,如有侵权或违规,请与小编联系!情况属实本人将予以删除!