



浏览器已经成为我每天都需要打交道的工具,然而对于这个我们的老朋友,即使一些 web 开发人员也对它的底层工作原理不是非常清楚,今天我们就来简单谈一谈浏览器的底层工作原理。
浏览器的主要功能
如果非要用一句话来概括浏览器的功能,那么浏览器就是一个请求资源,然后显示资源的软件。
这里的资源主要就是我们经常提到的 html,css,js,还有图片等。
浏览器共有的接口:
- 地址栏
- 前进后退按钮
- 刷新按钮
- 主页按钮
- 收藏按钮
通过这些接口我们就基本掌握了浏览器的基本操作。
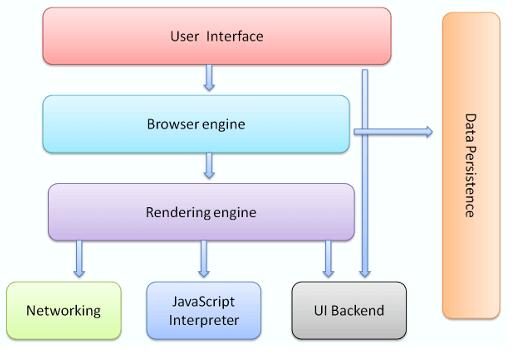
浏览器的架构
浏览器对外表现就是一个内容展示的容器,但是内部它却由很多组件组成。
- 用户接口(我们前面提到的那些公用操作接口)
- 浏览器引擎(UI 和渲染引擎的封装)
- 渲染引擎(负责显示请求的内容,根据 css 和 html 显示内容布局)
- 网络引擎(负责 http 请求,负责网络管理)
- UI 引擎(负责绘制基本 html 元素,比如下拉框,输入框等)
- js 解析引擎(解析和执行 JavaScript 代码)
- 数据存储引擎(存储 cookie,localStorage,IndexedDB,websql 等数据)
其中渲染引擎可以说是最重要的一部分,它一般决定着用户看到网页加载体验。
不同的浏览器使用不同的渲染引擎,之前的 IE 使用的是 Trident,Firefox 使用 Gecko,Chrome 使用 WebKit 等,目前现在基本都使用 Blink 引擎。
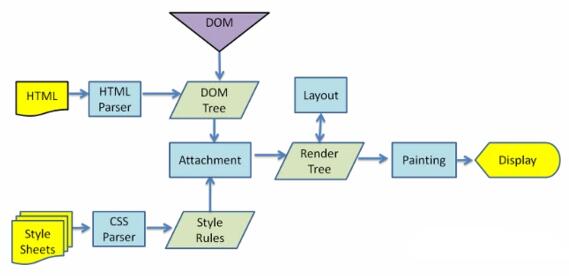
渲染引擎的工作流程大致是这样的。
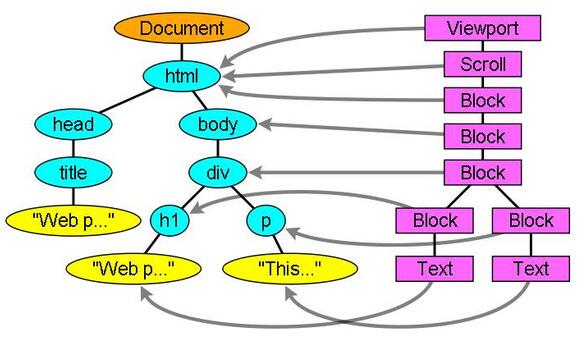
首选它获取到请求到的内容,然后开始解析 html 结构,将它们转换成 dom 树,然后渲染引擎解析 css 样式,生成一个 css 树,最后,根据样式信息和 html 结构生成 render 树,我们称之为渲染树。
渲染树主要包含了颜色,尺寸等视觉信息。构建渲染树之后,渲染树的每个节点将会经历布局,找到在屏幕上的坐标。然后 UI 引擎会绘制各个节点。
渲染树的构建是渐进的,它会根据结构一点点处理,尽量在屏幕上快速显示部分内容。
对于解析它主要包括两部分,一部分是词法分析,一部分是语法分析。
词法分析,主要是按照词汇表进行分析标记,构建块的集合。
语法分析,主要是根据词法规则构建解析树的解析器。
HTML 解析
html 的标记和语法都是被定义好的,因此在解析的时候只要按照规则即可。
html 文档格式是 DTD,它是一个上下文无关的文档格式。它更加宽容,可以省略一些标记,因此解析器处理起来会很复杂。
dom 树是由 dom 元素和属性构成的树形结构。其中 dom 和 html 中的标记是对应的。
<html>
<body>
<p> Hello World </p>
<div>
<img src="example.png"/>
</div>
</body>
<html>html 结构不能采用常规的自顶向下或者自底向上的解析器进行解析,因此它需要采用自定义的解析器进行解析,通过标记法和树构造进行解析。
例如,将初始状态标记为数据状态,然后从<开始进行标记,遇到 a-z 创建令牌,标记为 tag open 状态,直到遇到>,状态变回数据状态。
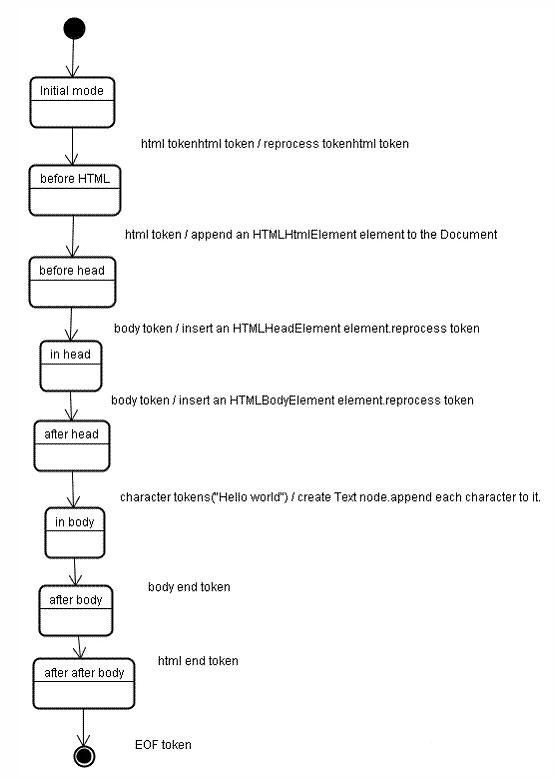
在创建解析器的时候,会创建文档对象,在解析树构造的时候,会向 dom 树添加元素。
标记法标记的节点会由解析树的构造函数进行处理。当元素被添加到 dom 树的时候,也会被添加到堆栈中。
在解析 dom 树的时候,js 引擎也会解析 js 脚本,dom 解析后,这些脚本会执行。
解析树是具有包容性的,当遇到一些错误的时候,它只会内部进行标记,并不会报错给用户。
css 解析
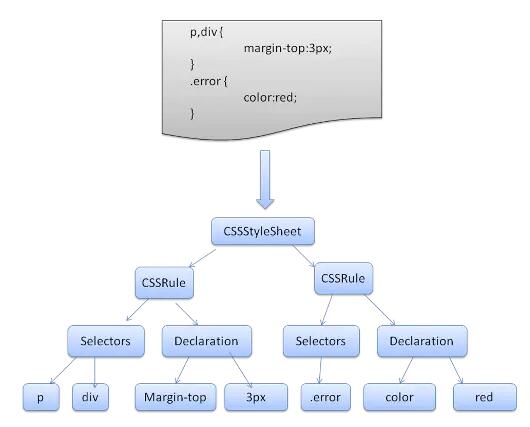
WebKit 引擎使用 Flex 和 Bison 解析器生成器从 CSS 语法文件自动创建解析器。Bison 创建了一个自底向上的 shift-reduce 解析器。每个 CSS 文件都被解析为一个样式表对象。每个对象都包含 CSS 规则。CSS 规则对象包含选择器和声明对象以及与 CSS 语法相对应的其他对象。
在之前的时候,web 模型是同步的,解析器需要获取资源,然后才能继续解析。目前是一个线程进行解析,一个线程用来获取文档剩下需要加载的资源文件。
构建渲染树需要计算每个渲染对象的视觉特性。这是通过计算每个元素的样式特性来完成的。该样式包括各种来源的样式表,内联样式和 html 中的视觉属性。
样式计算是非常复杂的,如果设计不佳的话,就会导致占用过多内存,因此很多浏览器采用通过添加规则树和上下文树来优化样式计算。
页面布局
在创建渲染器的时候,它没有位置和大小,然后我们需要计算它的位置和大小,这个过程被称为页面布局或者说叫做页面回流。
布局是一个递归过程,它从根渲染器开始,根据层次结构递归的遍历每个渲染器,然后计算它们的集合信息,最后布局它们。
布局分为全量布局和增量布局。所谓全量布局指的就是会影响所有渲染器的全局样式改变,比如字体改变。而增量布局指的是布局是异步完成的,渲染器通过触发器进行布局。
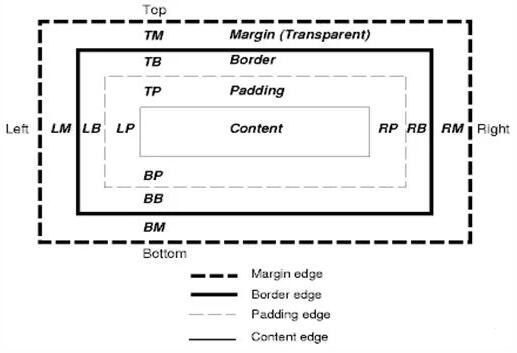
css 主要是通过盒子模型来布局。每个盒子都有一个内容区域和可选的周围区域,比如边框,边距。其中有些盒子是块状模型,有些是行内模型。
css 布局分为绝对定位和相对定位,绝对定位根据指定位置进行渲染,而相对定位则是根据其他元素的位置进行布局。
本文内容仅供个人学习/研究/参考使用,不构成任何决策建议或专业指导。分享/转载时请标明原文来源,同时请勿将内容用于商业售卖、虚假宣传等非学习用途哦~感谢您的理解与支持!
浏览器禁用了javascript,各种浏览器如何开启javascript的方法总汇
您的浏览器禁用了JS脚本运行,请启用该功能。怎么解除浏览器禁用js?这篇文章将总结整理各个浏览器如何开启、禁用javascript的方法总汇。
浏览器的回流与重绘 (Reflow & Repaint)
浏览器使用流式布局模型 (Flow Based Layout)。浏览器会把HTML解析成DOM,把CSS解析成CSSOM,DOM和CSSOM合并就产生了Render Tree。有了RenderTree,我们就知道了所有节点的样式,然后计算他们在页面上的大小和位置,最后把节点绘制到页面上。
IE6浏览器有哪些常见的bug,以及解决IE6常用bug的方法
IE6不支持min-height,解决办法使用css hack,ol内li的序号全为1,不递增。解决方法:为li设置样式display: list-item;定位父元素overflow: auto;,包含position: relative;子元素,子元素高于父元素时会溢出。解决办法:

css重设样式_清除浏览器的默认样式
由于不同的浏览器默认的样式也不同,所以在网页开发前设置一个公用样式,来清除各个浏览器的默认样式,已达到做的网页在各个浏览器中达到统一。
浏览器访问一个网站所经历的步骤
浏览器访问网站的步骤:Chrome搜索自身的DNS缓存、读取本地HOST文件、浏览器发起一个DNS的一个系统调用、浏览器获得域名对应的IP地址后,发起HTTP三次握手、TCP/IP连接建立起来、服务器端接受到了这个请求、浏览器根据拿到的资源对页面进行渲染
一个新式的基于文本的浏览器 Browsh
Browsh是一个纯文本浏览器,可以运行在大多数的TTY终端环境和任何浏览器。目前,终端客户端比浏览器客户端更先进。终端客户端即时更新和交付,以便于体验新的功能,例如,你可以观看视频。

浏览器内核有哪些?主流浏览器的所使用的内核介绍
一般说的浏览器内核是指浏览器最重要的核心部分,RenderingEngine,翻译成中文大概意思就是“解释引擎”,我们一般称为浏览器内核。由于不同的内核各自有一套自己的渲染网页和解释页面代码的机制,所以就会有一些问题存在。
程序员眼中的浏览器是什么样的?IE:有本事你卸了我啊
主流浏览器之争从上个世纪开就开始,已经持续了很长的时间。人们都在笑话IE,纷纷转向其它浏览器。今天,我向大家分享一下针对IE的搞笑图片,只是逗乐而已,喝杯咖啡,坐下来慢慢享受吧。
精打细算浏览器空闲时间
有时候我们希望在浏览器中执行一些低优先级的任务,比如记录统计数据、做一些耗时的数据处理等,暂且将其称为后台任务。这些任务跟动画计算、合成帧、响应用户输入等高优先级的任务共享主线程
深入浏览器事件循环的本质
浏览器的事件循环,前端再熟悉不过了,每天都会接触的东西。但我以前一直都是死记硬背:事件任务队列分为macrotask和microtask,浏览器先从macrotask取出一个任务执行,再执行microtask内的所有任务,接着又去macrotask取出一个任务执行
内容以共享、参考、研究为目的,不存在任何商业目的。其版权属原作者所有,如有侵权或违规,请与小编联系!情况属实本人将予以删除!