


众所周知, react 是通过管理状态来实现对组件的管理,而setState是用于改变状态的最基本的一个方法,虽然基础,但是其实并不容易掌握,本文将结合部分源码对这个方法做一个相对深入的解析。
基本用法
首先官方文档给出的,它的基本api:
// 接受2个参数,updater 和 callback
setState(updater[, callback])
// 第一种:updater可以是对象
setState({
key: val
}, newState=>{
// callback里可以获取到更新后的newState
})
// 第二种:updater可以是函数,返回一个对象值
setState((state, props)=>{
return {
key: val
}
}), newState=>{
})其中updater表示新的state值可以是返回一个对象的函数,也可以直接是一个对象。这部分的内容会通过浅比较被合并到state中去。
官方文档很明确的告诉我们:
setState 将对组件 state 的更改排入队列,并通知 React 需要使用更新后的 state 重新渲染此组件及其子组件。将 setState() 视为请求而不是立即更新组件的命令。为了更好的感知性能,React 会延迟调用它,然后通过一次传递更新多个组件。React 并不会保证 state 的变更会立即生效。
因此这个api的第二个参数callback,允许我们在setState执行完成后做一些更新的操作。
以上稍微回顾下基础知识部分,接下来我们正式开始详细探讨。
关于第一个函数参数
为了避免枯燥,我们带着问题来继续研究:
- 问题1:setState使用函数参数和对象参数有何区别?
在回答这个问题之前,请先看这个很常用的计时器的例子:
class Demo extends Component {
constructor(props) {
super(props);
this.state = {
count: 0 //初始值
};
}
increaseCount = () => {
this.setState({count: this.state.count + 1});
}
handleClick = ()=>{
this.increaseCount();
}
render() {
return (
<div className="App-header">
<button onClick={this.handleClick}>点击自增</button>
count:{this.state.count}
</div>
);
}
}这个代码看起来没有什么问题, 每次点击的时候也能自增1,完全符合预期效果。但是接下来! 我们希望通过改动handleClick,使得每次点击时,count自增2次,即:
handleClick = ()=>{
this.increaseCount()
this.increaseCount()
}这时候就会惊奇地发现,每次点击后,count还是自增1!问题出在哪里呢?
其实就是this.setState({count: this.state.count + 1});这种写法,由于前面提到了setState并非同步方法,所以这里的this.state.count并不能保证取到最新的值,这时候我们可以采用第二种写法:
// 这里我们用的函数参数的方式
increaseCount = () => {
this.setState((state)=>{return{count: state.count + 1}});
}这时候再试试,发现计时器可以按照预期效果执行,此时可以回答问题1了:如果setState时需要根据现有的state来更新新的state,那么应该使用函数参数来保证取到最新的state值。
答案1: 如果需要依赖当前state的值来更新下一个值的情况,需要使用函数作为参数,因为函数才能保证取到最新的state
关于批量更新
接下来要研究的,就是重头戏--setState更新过程,可能你看过的文档都告诉你,setState不会保证立即执行,而是会在某个时机批量更新所有的component。
那么问题来了: 为什么要设定这个批量机制,这个批量更新的过程到底又是如何执行的呢?
问题2: setStates为什么要设定批量更新机制?
这一点其实是处于大型应用的性能考虑,首先我们都知道,component的render是很耗时的。想象这种场景:
如果在某个复合组件由一个Parent和一个Child组成,在一个click事件中,Parent组件和Child组件都需要执行setState,如果没有批量更新的机制,那么首先父组件的setState会触发父组件的re-render 并且也会触发一次子组件的render,而子组件自己的setState还要触发一次它自身的re-render,这样会导致Child rerender两次,批量更新机制就是为了应对这种情况而产生的。
所以紧接着问题来了:
问题3:批量更新的过程是怎么执行的
为了回答这个问题,我整理了一下react中setState相关的源码(源码学习的步骤放在最后,有兴趣的小伙伴可以阅读,想直接看结论也可以略过),抛开一些对主流程影响不大的细节(去掉了一些错误抛出之类的代码,提高阅读效率),梳理出这样的一个大概的流程:(如果图被压缩看不清请点击https://www.processon.com/view/link/5de4a992e4b0df12b4afbc2a)
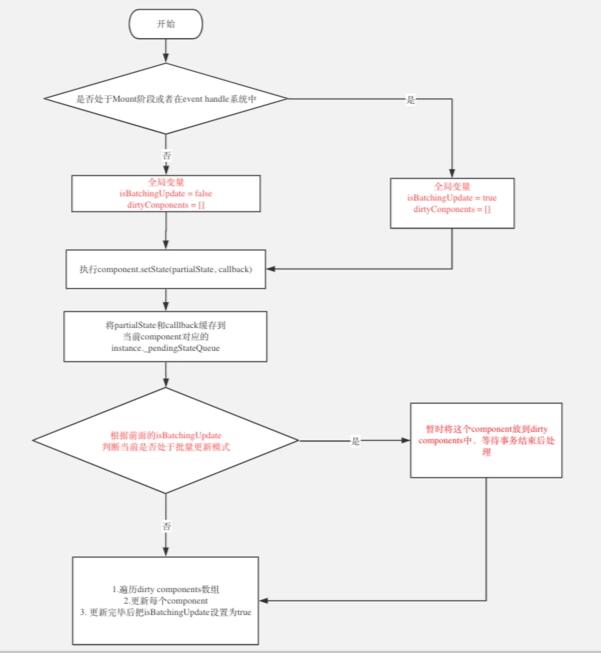
大致分为以下阶段:
- 首先判断执行setState的上下文环境,是否处于事件系统或者Mount周期中(这一点很重要!!!,后面会详细说明)
- 某个component执行setState
- 将新的state值partialState放入component对应的instance变量,这里简单介绍下,react在内存中为每个component创建了一个对应的instance对象,用来保存对应的一些属性,方便在更新以及其他过程时清晰的使用component对应的属性。
- 把缓存完变量的component,放入全局变dirtyComponents数组中,根据第一步的判断,判断目前是否要立即批量更新(如果是则直接更新,如果正处于handle event或者mount阶段,则等到阶段末尾再执行更新)
PS:这个过程中的关键步骤,react15.6的源码是使用了事务transition的写法来实现的,但是我认为对于解释setState的内容并非必要的,所以在本文不深入说明,剥离出来说明是为了让读者更容易理解。关于transition如果有必要,之后另外写文章说明
从以上的描述可以看到,我把判断执行setState的上下文环境放在开头,为什么要这样呢,接下来我们看另外一个有趣的例子,把最前面的计时器例子,稍微改变一下:
class Main extends Component {
constructor(props) {
super(props);
this.state = {
count: 0 //初始值
};
}
// 注意这个函数的改动
increaseCount = () => {
this.setState({count: this.state.count + 1});
console.log("第1次输出", this.state.count)
setTimeout(()=>{
this.setState({count: this.state.count + 1});
console.log("第2次输出", this.state.count)
this.setState({count: this.state.count + 1});
console.log("第3次输出", this.state.count)
},0)
}
handleClick = ()=>{
this.increaseCount();
}
render() {
return (
<div className="App-header">
<button onClick={this.handleClick}>点击自增</button>
count:{this.state.count}
</div>
);
}
}点击一下按钮之后,你能直接回答出上面的3次输出分别为多少吗?
答案:三次输出分别是0, 2, 3.
- 首先对于第一个console,对照上面的流程可知,setState执行时正处于click事件handle阶段,因此本次的更新将被放入更新队列并推迟更新,因此立即console无法获得最新的结果(类似的 如果我们在componentwillMount等生命周期阶段进行setState操作并立刻console也拿不到最新的值,因为也得走批量更新的路线); 所以第一次输出是0
- 其次第二个和第三个setState被放在setTimeout中,之前我在写异步事件队列的时候有说过,由于js的单线程,所有异步的操作都会被放在异步队列里,因此这两次调用setState时,函数调用栈和第一次是不一样的,它们并没有处于事件handle或者component Mount阶段,因此调用setState后,会立即执行批量更新(其实这时候也会把当前组件放入dirtyComponents中,只是此时恰好只有一个dirtyComponent,就会被执行批量更新),因此,后面两次的更新可以立刻拿到变更的值, 因此分别输出2和3。
其实到这里,我们就应该思考一个问题:
问题4: 为什么React特意在Mount过程和事件处理系统中安排批量更新机制呢?
答案4:回想起那么说过的设置批量更新的初衷,是为了减少整个应用内非必要的render从而提升性能,而最有可能需要render的时机其实就是:
- Mount一个component的阶段,本身存在render过程;
- 事件处理函数内部,经常有可能是多个组件,可能对于一个事件都进行了setState操作;
综上所述,不难猜想,其实React应该是希望在所有的地方都强制控制setState进行异步批量更新,而从目前版本(本文所用的源码是15.6)来说,能够逾越这个控制的,一般是只有手动setTimeout或者promise.then(常见于请求数据之后更新某个state)。
附录 相关源码阅读顺序
这部分是我个人关于setState在react源码的阅读顺序,仅供参考,希望可以对研究源码的小伙伴有所帮助:
// 1. react-15.6.0/src/isomorphic/modern/class/ReactBaseClasses.js
ReactComponent.prototype.setState = function(partialState, callback) {
// 省略错误捕获和异常处理
// updater实际是注入的 可以直接全局查找enqueueSetState方法
this.updater.enqueueSetState(this, partialState);
if (callback) {
this.updater.enqueueCallback(this, callback, 'setState');
}
};
// 通过全局查找enqueueSetState方法,找到以下内容
// 2.react-15.6.0/src/renderers/shared/stack/reconciler/ReactUpdateQueue.js
enqueueSetState:function(publicInstance, partialState){
// 这里可以简单理解为: 当前component上保存一个_pendingStateQueue数组,值为partialState,internalInstance实际上是内存中与当前component对应的一个变量,专门用来存储当前component对应的属性
var internalInstance = getInternalInstanceReadyForUpdate(
publicInstance,
'setState',
);
if (!internalInstance) {
return;
}
var queue =
internalInstance._pendingStateQueue ||
(internalInstance._pendingStateQueue = []);
queue.push(partialState);
enqueueUpdate(internalInstance);
}
// 查找enqueueUpdate方法
// 3. react-15.6.0/src/renderers/shared/stack/reconciler/ReactUpdateQueue.js
enqueueUpdate: function enqueueUpdate(internalInstance) {
ReactUpdates.enqueueUpdate(internalInstance);
}
// 查找ReactUpdates的enqueueUpdate
// 4.react-15.6.0/src/renderers/shared/stack/reconciler/ReactUpdates.js
// 这里if (!batchingStrategy.isBatchingUpdates)便是批量更新执行的关键分支语句
ReactUpdates.enqueueUpdate = function (component){
// 如果不在批量更新 那直接执行
if (!batchingStrategy.isBatchingUpdates) {
batchingStrategy.batchedUpdates(enqueueUpdate, component);
return;
}
// 如果在 那存起来 延后执行
dirtyComponents.push(component);
if (component._updateBatchNumber == null) {
component._updateBatchNumber = updateBatchNumber + 1;
}
}
// 5.先看!batchingStrategy.isBatchingUpdates路线查找
// react-15.6.0/src/renderers/shared/stack/reconciler/ReactDefaultBatchingStrategy.js
// 这里要很注意,每次调用batchedUpdates 都会使ReactDefaultBatchingStrategy.isBatchingUpdates 变成 true;所以必须全局查找 调用batchingStrategy.batchedUpdates()的地方,查找后会发现是在Mount和eventHandle过程,这也就是得出前面流程图里,得出第一步骤的关键点
var ReactDefaultBatchingStrategy = {
isBatchingUpdates: false,
/**
* Call the provided function in a context within which calls to `setState`
* and friends are batched such that components aren't updated unnecessarily.
*/
batchedUpdates: function(callback, a, b, c, d, e) {
var alreadyBatchingUpdates = ReactDefaultBatchingStrategy.isBatchingUpdates;
ReactDefaultBatchingStrategy.isBatchingUpdates = true;
// The code is written this way to avoid extra allocations
if (alreadyBatchingUpdates) {
return callback(a, b, c, d, e);
} else {
// 这个地方用了transaction的写法,看起来稍微有点绕,建议稍微了解下transaction的概念
return transaction.perform(callback, null, a, b, c, d, e);
}
},
};
// 6.flushBatchedUpdates 遍历dirtyComponents 循环执行runBatchedUpdates
ar flushBatchedUpdates = function() {
while (dirtyComponents.length || asapEnqueued) {
if (dirtyComponents.length) {
var transaction = ReactUpdatesFlushTransaction.getPooled();
transaction.perform(runBatchedUpdates, null, transaction);
ReactUpdatesFlushTransaction.release(transaction);
}
if (asapEnqueued) {
asapEnqueued = false;
var queue = asapCallbackQueue;
asapCallbackQueue = CallbackQueue.getPooled();
queue.notifyAll();
CallbackQueue.release(queue);
}
}
}
// 这是最后遍历更新的地方 其实没什么好看的了
function runBatchedUpdates(){
// 遍历所有的dirtyComponents 依次更新component 并缓存callbacks
}小结
(看了一眼上一篇又过去了接近3个月-_-!)本文主要针对setState的批量更新过程和常见几个问题做了一些相关解析,希望对大家有帮助,关于transaction以及具体的更新比对过程后续找机会另外说明(理直气壮鸽子王-_-),如果读者有感兴趣的其他话题也欢迎提出来探讨。
原文:https://segmentfault.com/a/1190000021178528
本文内容仅供个人学习/研究/参考使用,不构成任何决策建议或专业指导。分享/转载时请标明原文来源,同时请勿将内容用于商业售卖、虚假宣传等非学习用途哦~感谢您的理解与支持!
如何优雅的设计 React 组件
如今的 Web 前端已被 React、Vue 和 Angular 三分天下,尽管现在的 jQuery 已不再那么流行,但 jQuery 的设计思想还是非常值得致敬和学习的,特别是 jQuery 的插件化。
React深度编程:受控组件与非受控组件
受控组件与非受控组件在官网与国内网上的资料都不多,有些人觉得它可有可不有,也不在意。这恰恰显示React的威力,满足不同规模大小的工程需求。
React框架学习_关于React两种构建应用方式选择
一般在传统模式下,我们构建前端项目很简单。就是下载各种js文件,如JQuery、Echart等,直接放置在html静态文件。Webpack则是JavaScript中比较知名的打包工具。这两个构建工具构成了React应用快速搭建的基础。

Gatsby.js_一款基于React.js静态站点生成工具
Gatsby能快速的使用 React 生态系统来生成静态网站,可以结合React Component、Markdown 和服务端渲染来完成静态网站生成让他更强大。
React创建组件的三种方式及其区别
React推出后,出于不同的原因先后出现三种定义react组件的方式,殊途同归;具体的三种方式:函数式定义的无状态组件、es5原生方式React.createClass定义的组件、es6形式的extends React.Component定义的组件
react生命周期详解_深入理解React生命周期
React主要思想是通过构建可复用组件来构建用户界面,每个组件都有自己的生命周期,它规定了组件的状态和方法需要在哪个阶段改变和执行。所谓组件就是有限状态机,,表示有限个状态以及在这些状态之间的转移和动作行为的模型。
React + Webpack 构建打包优化
React 相关的优化:使用 babel-react-optimize 对 React 代码进行优化,检查没有使用的库,去除 import 引用,按需打包所用的类库,比如 lodash 、echarts 等.Webpack 构建打包存在的问题两个方面:构建速度慢,打包后的文件体积过大

react router中页面传值的三种方法
这篇文章主要介绍React Router定义路由之后如何传值,有关React和React Router 。react router中页面传值的三种方法:props.params、query、state
react 高阶组件的 理解和应用
react 高阶组件简单的理解是:一个包装了另一个基础组件的组件。高阶组件的两种形式:属性代理(Props Proxy)、反向继承 (Inheritance Inversion)
react中的refs属性的使用方法
React 支持一种非常特殊的属性 Ref ,你可以用来绑定到 render() 输出的任何组件上。这个特殊的属性允许你引用 render() 返回的相应的支撑实例( backing instance )。这样就可以确保在任何时间总是拿到正确的实例
内容以共享、参考、研究为目的,不存在任何商业目的。其版权属原作者所有,如有侵权或违规,请与小编联系!情况属实本人将予以删除!