


人工智能先驱、贝叶斯网络之父、美国计算机科学家 Judea Pearl 在最近的一篇论文中解释了基于数据统计的机器学习系统的一些局限性。要理解“为什么”,并回答“如果……会怎样”之类的问题,我们需要某种因果模型。在社会科学领域,尤其是流行病学中,一种名为“结构因果模型”(SCM)的革命性数学框架已经被广泛采用。Pearl 介绍了这种模型可以处理的七个任务,虽然这些任务对于关联机器学习系统来说有些遥不可及。
三层式因果模型层级
因果模型理论所揭示的一个有用见解是根据每个类能够回答的问题类型对因果信息进行分类。这种分类形成了三层式的结构,只有当层级 j(j >= i)的信息可用时才能回答层级 i(i = 1,2,3)的问题。
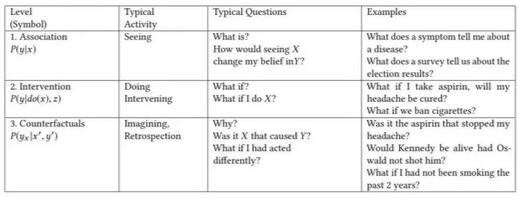
最低(第一)层被叫作关联(Association),它涉及由裸数据定义的纯统计关系。大多数机器学习系统运行在这一层上。
第二层被叫作干预(Intervention),不仅涉及到能看到什么,还涉及你可能采取的行动(干预措施)有哪些影响。我认为增强学习系统是运行在这个层上(例如,“如果我把骑士移到这个方格会怎样?”)。增强学习系统倾向于在定义良好的环境中运行,而干预层也包含了更多的开放性挑战。作为例子,Pearl 提了一个问题:“如果我们将价格翻倍,将会发生什么?”
这些问题无法单独从销售数据中得到解答,因为它们涉及客户行为的变化(对新的价格作出反应)。
我个人认为,如果销售数据可以显示出先前价格上涨所带来的影响,那么很可能可以基于销售数据构建一个预测模型。Pearl 的反驳论点是,除非我们能够准确地复制之前价格达到当前价格两倍时的市场条件,否则我们无法真正知道客户会做出怎样的反应。
最上面一层被称为反事实(Counterfactual),解决的是“如果……会怎样”问题。当规模很小时,序列到序列生成模型就能够解决问题。我们可以“重放”序列的开头,修改下一个数据值,然后查看输出会发生什么变化。
这些层构成了层次结构,介入性问题无法从纯粹的观察性信息中得到回答,而反事实性问题无法从纯粹的介入性信息中得到回答(例如,我们无法对已经接受了药物的受试者重新进行实验,以便知道如果不为受试者提供药物会怎样)。在层级 j 回答问题的能力意味着我们也可以回答层级 i(<=j)的问题。
这种层次结构及其所包含的形式限制解释了为什么基于关联的机器学习系统无法推理动作、实验和因果解释。
结构因果模型
结构因果模型(SCM)结合了图形建模、结构方程、反事实和介入逻辑。
我们可以使用这些工具正式表达因果问题,以图解和代数形式编纂我们现有的知识,然后利用数据来估计答案。此外,当现有知识状态或现有数据不足以回答我们的问题时,这个理论会警告我们,然后建议其他知识或数据来源,让问题变得可回答。
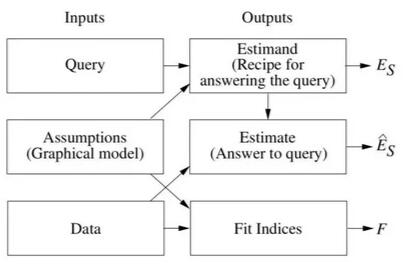
SCM“推理引擎”将假设(以图形模型的形式)、数据和查询作为输入。
例如,下图显示 X(例如服用药物)对 Y 具有因果效应(例如恢复),第三变量 Z(例如性别)影响 X 和 Y。
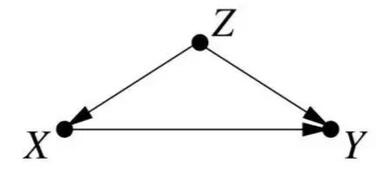
这让我想起了我在贝叶斯决策方面看到的模型。
有三个输出:
- Estimand 是一个数学公式,根据假设提供从任何可用假设数据中回答查询的方法。
- Estimate 是查询的答案,以及置信度的统计估计。
- 一组拟合指数(Fit Indices)用于衡量数据与假设的兼容程度。如果编码的假设没有任何可测试的含义,则该集合为空。
如果在给定模型假设的情况下无法回答查询,则将其声明为“无法识别”。
所幸的是,我们已经开发出有效且完整的算法来确定可识别性,并为各种反事实查询和各种数据类型生成估计。
SCM 可以为我们做些什么?
Pearl 并没有深入研究 SCM 的运作细节,而是列举了 SCM 框架提供的七种因果推理工具。
1. 透明度和可测试性
透明度让分析师能够辨别出编码假设是否合理,并且源于紧凑的图形表示。
可测试性是通过一个叫作 d-separation 的图形标准来增强的,这个标准提供了原因和概率之间的基本连接。它告诉我们,对于模型中任意给定的路径模式,我们应该期望在数据中找到哪些依赖模式。
2. do-calculus 和混淆控制
这里的混淆似乎是指潜在变量的存在,潜在变量是两个或多个已观察到的变量的未知成因。如何选择协变量来控制混淆早在 1993 年就已有定论,后来的 do-calculus 在可行的情况下预测政策干预的效果,并在假设不允许预测时退出。
3. 反事实
现代因果关系研究的最大成就之一就是通过图形表示形式化反事实推理。每个结构方程模型都确定了每个反事实句子的真实性。因此,如果句子的概率是从实验或观察研究或二者的组合估计出来的,那么我们就可以基于分析做出决策。
4. 调解分析
调解分析涉及发现中间机制,通过这些中间机制可以将原因传给结果。我们可以发起诸如“X 对 Y 的影响的哪些部分是由变量 Z 调节的”之类的查询。
5. 适应性、外部有效性和样本选择偏差
健壮性问题需要环境的因果模型,并且不能在 Association 层面处理… do-calculus 提供了一种完整的方法用于克服由于环境变化而引起的偏差。它既可用于重新调整学习策略以规避环境变化,也可用于控制由非代表性样本引起的偏差。
6. 从不完整的数据中恢复
通过使用 SCM 因果模型,我们有可能对条件进行正规化。在这些条件下,可以从不完整的数据中恢复因果关系和概率关系,并且只要满足条件,就可以为所需关系生成一致的估计。
7. 因果发现
d-separation 标准让我们能够检测并列举给定模型的可测试含义。我们还可以推断出与数据兼容的模型集。还有一些方法用于发现因果方向性。
结 论
一方面,这篇文章看起来像是在推广 SCM:“关联机器学习”方法与层次结构中的关联层紧密联系。另一方面,丰富的因果推理理论似乎可以为传统的机器学习方法提供很多补充。Pearl 肯定也是这么认为的!
鉴于因果模型对社会科学和医学科学产生的变革性影响,我们很自然会期待机器学习技术也会发生类似的变革。我期待这种共生产生的系统能够使用原生因果语言与用户沟通,并且借助这种能力成为下一代 AI 的主导。
原文链接:https://blog.acolyer.org/2018/09/17/the-seven-tools-of-causal-inference-with-reflections-on-machine-learning/
本文内容仅供个人学习/研究/参考使用,不构成任何决策建议或专业指导。分享/转载时请标明原文来源,同时请勿将内容用于商业售卖、虚假宣传等非学习用途哦~感谢您的理解与支持!
nodejs 通过钉钉群机器人推送消息
最近在用 nodejs 写,之前的 nodejs 爬虫代码用 js 写的,感觉可维护性太差,也没有智能提示,于是把js改用ts(typescript)重写一下,提升代码质量。爬虫启动之后不定期会出现验证码反爬虫,需要输入验证码才能继续
机器学习建模的几点思考与总结
机器学习现在在很多地方都是十分流行,无论现在的你是否从事建模工作,还是你将来想从事相关工作,对于从业者可以从中看出一些同感与意见,对于未来从业者可以了解这个职业到底是做些什么。
值得探索的 8 个机器学习 JavaScript 框架
Deeplearn.js是Google发布的一个开源的机器学习JavaScript库,可用于不同的目的,例如在浏览器中训练神经网络,理解ML模型,用于教育目的等。你可以在推理模式中运行预先训练的模型
内容以共享、参考、研究为目的,不存在任何商业目的。其版权属原作者所有,如有侵权或违规,请与小编联系!情况属实本人将予以删除!