问题描述
fetch 发送一个请求,请求登录过期返回 302,浏览器自动重定向到 Response Headers 的 Location 登录页面。Location 对应的服务器不接受跨域请求,因此页面报错。
尝试在 fetch 的回调函数处理,一旦 fetch 的 response status 是 302 就跳转到 Location 页面, 但是不论在fetch的回调函数中做任何事情,都执行不到。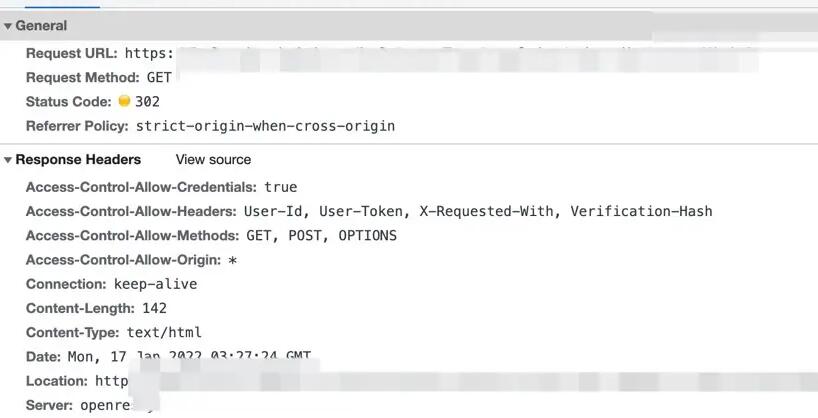
什么是 HTTP 状态码 302 ?
HTTP 302 重定向状态码表明请求的资源被暂时的移动到了由Location头部指定的 URL 上。浏览器会重定向到这个URL, 但是搜索引擎不会对该资源的链接进行更新。
使用场景:
- 在 OAuth 流程中,302 经常使用;
- 有时候请求的资源无法从其标准地址访问,但是却可以从另外的地方访问。在这种情况下可以使用临时重定向。
- 搜索引擎不会记录该新的、临时的链接。在创建、更新或者删除资源的时候,临时重定向也可以用于显示临时性的进度页面。
痛点:浏览器 自动 发起对 重定向地址的请求,js 无法插手干预。
fetch 为什么不能拦截302?
一般请求的流程:
- fetch 发送请求;
- 服务器返回 response 并且带有状态码(比如200) ;
- 浏览器接收到响应,结果递交给fetch;
- 从 fetch 的回调函数获取相应数据;

302 临时重定向请求的流程是:
- fetch 发送请求;
- 服务器返回 response (带有location) 并且带有 302 状态码;
- 浏览器接收到响应,自动从302响应的头信息的重定向地址中取到 location 进行跳转;
对于重定向,当浏览器检查到 headers 中存在 Location,会直接进行跳转,不会告知任何请求发送者(fetch),这时候发送者会以为请求还在处理中。所以此时的 fetch 的 then 和catch 都捕获不到信息
如何解决?
1. 配置 fetch 的 redirect
fetch 的 options 配置项redirect,用于配置可用的 redirect 模式。
redirect 的值有:
- follow:默认, 自动重定向;
- error:如果产生重定向将自动终止并且抛出一个错误;
- manual:手动处理重定向;
error
如果产生重定向将自动终止并且抛出一个错误。此错误可以在 fetch catch 回调函数中捕获:TypeError: Failed to fetch。
fetch 只有服务器错误才调用 catch,其他都会调用 then 函数,那么 302 为什么会调用catch?
不是 302 导致 catch 被调用而是重定向后的请求的 response 导致 catch 被调用。
manual
手动处理重定向。通过这种方法只能知道发生了重定向,但是 response 的内容非常有限,无法获取到具体的信息。
2. 后端改写状态码,前端手动处理
目前的 302 是对 404 的改写,那么如果我们将 404 改写成自定义状态码,然后前端捕获到这个状态码后,进行手动处理。这种方法则需要前后端的同学都做处理。
301 和 302 状态码区别
301:永久重定向。一旦请求发往某个URL,状态码返回301,那么浏览器就会自动跳转到 header中 Location 对应的 url。下次请求,再次向 location 对应的 url 发送请求。
- 之后每次请求都会跳转到 location 对应的url。没有例外。
- 浏览器可以缓存从这个 url 获取的响应。
302:临时重定向。请求的资源临时从不同的url获取。一旦请求发往某个URL,状态码返回302,那么浏览器就会自动跳转到 header中 Location对应的 url。但是下次再次请求的时候向原来的url发请求。
- 每次请求不能确定是否向 Location 的 url 发请求,因此需要先想原来的 url 发送请求确定。
- 浏览器不可缓存从重定向的 url 获取到的响应。
重定向可以用来set cookie
浏览器如果发现当前请求的响应要重定向,则会直接忽略掉 response 的 body,无法在开发者工具中的 network 面板上看到 body。虽然重定向请求的 body 会被浏览器忽略掉,但重定向请求响应的头部仍然可以发挥作用。
例如一个请求服务端返回 302 的同时 set-cookie,那么浏览器可以在发起跳转之前在当前页面的域下set cookie。即使因为 302 跳转到其他域了,也仍然可以set cookie。
- 用户访问 a 域名
- 后端返回302,location是 b 域名,同时set-cookie: cookieA
- 浏览器在 a 域名下种上cookie: cookieA,然后向 b 域名发起请求
- 后端返回 302,location 是a 域名,同时 set-cookie: cookieB
- 浏览器在 b 域名下种上cookie: cookieB,然后向 a 域名发起请求
这里相当于是实现了这样一种效果:一次请求即可向不同域名种下cookie(重定向是后端控制的,前端透明,相当于只有一次请求的效果)。
如果不用重定向的话,可能会考虑配置CORS发一个跨域请求set cookie,但CORS一旦涉及到cookie这种 credentials 信息,就会出现各种各样的限制,实际很难发挥效果。
其实跨域 set cookie 还可以用浏览器的 beacon api 实现,当然也是有一些限制的
重定向可以有多次,比如连续的302, 就是 location 对应的 URL 又返回了 302 和新的location,如此重复直到不再跳转位置。为了防止出现无限重定向的情况,重定向的次数是有上限的。Chrome 浏览器的重定向次数是20,超过20次重定向就会报ERR_TOO_MANY_REDIRECT错误。
来自:https://segmentfault.com/a/1190000041300989
Fetch -- http请求的另一种姿势
传统Ajax是利用XMLHttpRequest(XHR)发送请求获取数据,不注重分离的原则。而Fetch API是基于Promise设计,专为解决XHR问题而出现。fetch API看起来简单,却是js语法不断增强提高带来的改善。
JavaScript中fetch接口的用法使用
fetch就是XMLHttpRequest的一种替代方案。如果有人问你,除了Ajax获取后台数据之外,还有没有其他的替代方案?这是你就可以回答,除了XMLHttpRequest对象来获取后台的数据之外,还可以使用一种更优的解决方案fetch。
当fetch遇到302状态码,会发生什么?
当fetch遇到302状态码,会发生什么?fetch不能拦截302,浏览器会自动从302响应的头信息的重定向地址中取到数据。针对认证的情况,后端可以返回401状态码,让前端去检查返回的状态码并据此执行相应操作。
Fetch使用
Fetch API 提供了一个获取资源的接口(包括跨域请求)。任何使用 过 XMLHttpRequest 的人都能轻松上手,但新的API提供了更强大和 灵活的功能集。Fetch 提供了对 Request 和 Response (以及其他与网络请求有关的)对象的通用定义。
fetch使用的常见问题及其解决办法
fetch默认不携带cookie配置其 credentials 项,其有3个值:omit: 默认值,忽略cookie的发送;same-origin: 表示cookie只能同域发送,不能跨域发送;include: cookie既可以同域发送,也可以跨域发送
fetch API
fetch:一个获取资源的接口,类似于ajax,是基于 Promise之上设计,旧版本IE 完全不支持,须借助 polyfill来兼容,提供了对 Request 和 Response 对象的通用定义
fetch使用,ajax替代方案
Fetch 提供了一个 JavaScript接口,用于访问和操纵HTTP管道的部分,例如请求和响应。它还提供了一个全局 fetch()方法,该方法提供了一种简单,合理的方式来跨网络异步获取资源。
TypeScript Fetch封装使用
Fetch API 提供了一个 JavaScript接口,用于访问和操纵HTTP管道的部分,例如请求和响应。它还提供了一个全局 fetch()方法,该方法提供了一种简单,合理的方式来跨网络异步获取资源
通过fetch发送 post 请求下载文件
最近遇到一个下载的需求,由于 url 参数太长(常用的下载方法 a 标签或者 location.href 的方法都是 get 请求,get 请求参数长度有限制),无法下载,考虑了好几种方案,最终还是觉得通过 ajax 的 POST 方法进行下载,比较容易实现
Js中使用fetch进行异步请求
在 AJAX 时代,进行 API 等网络请求都是通过 XMLHttpRequest 或者封装后的框架进行网络请求。 现在产生的 fetch 框架简直就是为了提供更加强大、高效的网络请求而生,虽然在目前会有一点浏览器兼容的问题
内容以共享、参考、研究为目的,不存在任何商业目的。其版权属原作者所有,如有侵权或违规,请与小编联系!情况属实本人将予以删除!