最近对slow-json-stringify的源码研究了一下,本文将对源码中函数的作用进行讲解。下文的源码是2.0.0版本的代码。
简介
JSON.stringify可以把一个对象转化为一个JSON字符串。slow-json-stringify开源库是对上述功能进行了一个时间上的优化。
因为JavaScript是动态类型的语言,所以一个对象的属性值的类型在运行的时候才能确定,因此执行JSON.stringify会有很多和确定变量类型相关的工作。
那么,如果我们事先可以知道JSON的格式,是不是就可以缩减一些时间?slow-json-stringify正是基于这个思路去做的。所以,你需要提供一个说明属性值类型的schema,它会根据schema生成一个单独的stringify方法。

基本原理就是根据提供的schema,把字符串分割成两部分,chunks和queue:
- chunks里面用于存放字符串中不变的部分
- queue存放生成动态属性值相关的信息
当序列化实际对象的时候,再把这两部分拼接起来。
使用
schema定义
// 我们需要stringify的对象
var obj = {
a: 'world', // 字符串类型
b: 42, // 数字类型
c: true, // 布尔类型
d: [ // 数组中每一项都是同样的结构
{
e: 'value1',
f: 3
},
{
e: 'value2',
f: 4
}
]
}
var schema = {
a: attr('string'), // 不是'string',使用了它提供的attr方法
b: attr('number'), // 不是'number',使用了它提供的attr方法
c: attr('boolean'), // 不是'boolean',使用了它提供的attr方法
d: attr('array', sjs({
e: attr('string'),
f: attr('number')
}))
}
var stringify = sjs(schema) // sjs函数针对每一个schema生成一个单独的stringify方法
stringify(obj) // "{"a":"world","b":42,"c":true,"d":[{"e":"value1","f":3},{"e":"value2","f":4}]}"简化版本代码分析
刚开始分析的时候,我们可以大致了解下每个函数的功能,不用太考虑各种细节,等我们把整体流程了解完成之后,再看细节部分。
我们以下面这个最简单的schema为例进行讲解:
var schema = {
a: attr('string'),
b: attr('number'),
c: attr('boolean')
}在上面使用的时候,我们发现主要用了两个函数,attr和sjs(slow json stringify的缩写),我们先看下attr函数完整版:
const attr = (type, serializer) => {
if (!TYPES.includes(type)) { // 容错处理,可以先不考虑
throw new Error(`Expected one of: "number", "string", "boolean", "null". received "${type}" instead`);
}
const usedSerializer = serializer || (value => value); // 自定义每个属性的stringify方法,可以先不考虑
return {
isSJS: true,
type,
serializer: type === 'array'
? _makeArraySerializer(serializer) // 数组类型,做特殊处理,可以先不考虑
: usedSerializer,
};
};简化后的版本如下:
const attr = (type, serializer) => {
const usedSerializer = value => value;
return {
isSJS: true,
type,
serializer: usedSerializer,
};
};可以看到attr接受两个参数:类型和自定义序列化函数,上述schema实际如下:

sjs
sjs函数完整版代码如下:
const sjs = (schema) => {
const { preparedString, preparedSchema } = _prepare(schema);
const queue = _makeQueue(preparedSchema, schema);
const chunks = _makeChunks(preparedString, queue);
const selectChunk = _select(chunks);
...
};sjs函数用了多个方法,_prepare, _makeQueue, _makeChunks, _select。接下来我们一一介绍。
_prepare
const _prepare = (schema) => {
const preparedString = JSON.stringify(schema, (_, value) => {
if (!value.isSJS) return value;
return `${value.type}__sjs`;
});
const preparedSchema = JSON.parse(preparedString);
return {
preparedString,
preparedSchema, // preparedString对应的json对象
};
};_prepare(schema)
// preparedString: "{"a":"string__sjs","b":"number__sjs","c":"boolean__sjs"}"
// preparedSchema: {a:"string__sjs",b:"number__sjs",c:"boolean__sjs"}
// schema: {a:attr('string'),b:attr('number'),c:attr('boolean')}对比下会发现_prepare把attr('type')形式转化成了type_sjs形式。为什么这么转呢?我们发现只要把preparedString里面的type_sjs替换成真正的值就可以了。所以,我们可以把prepareString里面不变的部分和变的部分分开,然后按照顺序再把他们拼接起来:不变的部分+变的部分+不变的部分+变的部分+...+不变的部分。所以就有了下面这两个方法:
- _makeQueue是把变的部分按照顺序提取成一个数组。
- _makeChunks是把不变的部分按照顺序提取成一个数组。
_makeQueue
const _makeQueue = (preparedSchema, originalSchema) => {
const queue = [];
(function scoped(obj, acc = []) {
// 前面_prepare生成的preparedSchema把属性值变成了type__sjs的形式,所以如果属性值包含__sjs,我们可以认为这就是变量部分
if (/__sjs/.test(obj)) {
const usedAcc = Array.from(acc);
const find = _find(usedAcc); // 从实际对象中获取这个变量值的方法,usedAcc是这个属性数组形式的访问路径
const { serializer } = find(originalSchema); // 从原始schema获取序列化方法
queue.push({
serializer, // 该属性值序列化的方法
find, // 从对象中获取属性值的方法
name: acc[acc.length - 1], // 属性名
});
return;
}
return Object
.keys(obj)
.map(prop => scoped(obj[prop], [...acc, prop]));
})(preparedSchema);
return queue;
};_makeQueue(_prepare(schema).preparedSchema, schema)
可以看到find方法是我们获取实际属性值的方法。我们看下_find函数:
const _find = (path) => {
const { length } = path;
let str = 'obj';
for (let i = 0; i < length; i++) {
// 简单的容错
str = str.replace(/^/, '(');
str += ` || {}).${path[i]}`;
// 如果不做容错处理,可以直接用下面的
// str += `.${path[i]}`
}
return eval(`((obj) => ${str})`);
};path是对象某个属性的访问路径上的所有属性名组成的数组,比如对象:
var hello = {
a: {
b: {
c: 'world'
}
}
}属性值'world'的访问路径就是['a', 'b', 'c'],我们把这个path传给_find,就会给我们返回一个使用eval动态生成的函数(obj) => (((obj.a || {}).b || {}).c。
如果使用上面我说的不做容错处理的版本,那么返回的函数就是(obj) => obj.a.b.c。
_makeChunks
const _makeChunks = (str, queue) => str
.replace(/"\w+__sjs"/gm, type => (/string/.test(type) ? '"__par__"' : '__par__'))
.split('__par__')
.map((chunk, index, chunks) => {
const matchProp = `("${(queue[index] || {}).name}":(\"?))$`;
const matchWhenLast = `(\,?)${matchProp}`;
const isLast = /^("}|})/.test(chunks[index + 1] || '');
const matchPropRe = new RegExp(isLast ? matchWhenLast : matchProp);
const matchStartRe = /^(\"\,|\,|\")/;
return {
flag: false, // 表明前面的属性值是不是undefined
pure: chunk,
prevUndef: chunk.replace(matchStartRe, ''),
isUndef: chunk.replace(matchPropRe, ''),
bothUndef: chunk
.replace(matchStartRe, '')
.replace(matchPropRe, ''),
};
});上面的咋一看挺复杂,好多正则正则表达式,他们是用来处理属性值是undefined的情况。
JSON.stringify转换成json字符串的过程中,如果这个属性值是undefined,这个属性不会出现在最终的字符串中,如下:
JSON.stringify({a: 'hello', b: undefined}) // "{"a":"hello"}"我们可以先不考虑属性值是undefined的情况,那么,_makeQueue可以简化如下:
// str是前面通过_prepare生成的preparedString
const _makeChunks = (str) => str
.replace(/"\w+__sjs"/gm, type => (/string/.test(type) ? '"__par__"' : '__par__'))
.split('__par__')
.map((chunk, index, chunks) => {
return {
flag: false, // 表明前面的属性值是不是undefined
pure: chunk
};
});var preparedString = _prepare(schema).preparedString
// "{"a":"string__sjs","b":"number__sjs","c":"boolean__sjs"}"
_makeChunks(preparedString)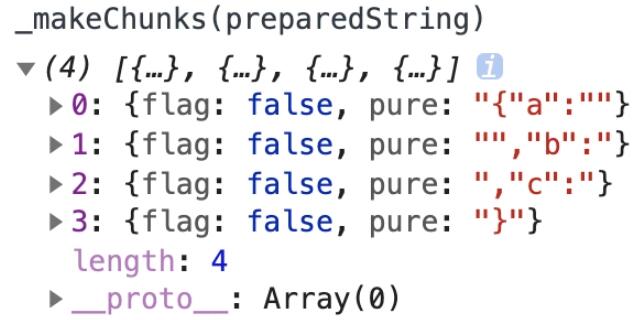
通过结果会发现_makeChunks就是把不变的部分按照顺序提取成一个数组。我们知道字符串stringify之后,属性值是被双引号包围的,数字或者布尔值stringify之后,属性值是不被双引号包围的,所以string__sjs两边的双引号是需要保留放在chunk里面的,数字和布尔类型是需要去掉双引号的。这就是上面replace方法的作用。然后再以__par__分割字符串。
观察上面截图中pure属性,会发现a属性值那比b和c多一个双引号。这个就是replace方法在起作用。
select方法
const _select = chunks => (value, index) => {
const chunk = chunks[index];
if (typeof value !== 'undefined') {
if (chunk.flag) {
return chunk.prevUndef + value;
}
return chunk.pure + value;
}
chunks[index + 1].flag = true;
if (chunk.flag) {
return chunk.bothUndef;
}
return chunk.isUndef;
};前面我们说了不考虑属性值是undefined的情况,所以第一个if判断就是true,就不用考虑下面的情况了。而chunk的flag是表明前面的属性值是不是undefined的,在不考虑属性值是undefined的情况下,这个flag永远是false。这两步精简后的_select函数如下:
const _select = chunks => (value, index) => {
const chunk = chunks[index];
return chunk.pure + value;
};chunk.pure就是前面_makeChunks生成的,使用__par__分割生成的字符串。
_select方法用来拼接不变的部分chunk和通过queue得到的实际属性值。
下面我们接着讲sjs函数:
const sjs = (schema) => {
const { preparedString, preparedSchema } = _prepare(schema);
const queue = _makeQueue(preparedSchema, schema);
const chunks = _makeChunks(preparedString, queue);
const selectChunk = _select(chunks);
const { length } = queue;
return (obj) => {
let temp = '';
let i = 0;
while (true) {
if (i === length) break;
const { serializer, find } = queue[i];
const raw = find(obj); // 找到这个属性的实际属性值
temp += selectChunk(serializer(raw), i);
i += 1; // 处理下一个属性值
}
const { flag, pure, prevUndef } = chunks[chunks.length - 1]; // 拼接最后一个不变的部分
return temp + (flag ? prevUndef : pure);
};
};sjs函数返回了一个函数,这个函数的参数是我们将要stringify的json对象。这个函数会通过循环的方式遍历queue数组,queue数组存储的就是变量的部分。通过find方法找到变量的原始值,然后通过serializer方法返回自定义的值,通过selectChunk方法返回该属性值前面不变的部分+属性值。
最后在加上最后一个不变的部分,这个过程就完成了。我们会发现queue的长度始终比chunks的长度小一。
完整版本代码分析
我们通过几个例子来对应看下在简化版本我们忽略的部分
例子一:嵌套对象
var schema = {
a: attr('string'),
b: attr('number'),
c: {
d: attr('string'),
e: attr('number')
}
}_makeQueue
我们来分析下_makeQueue方法下面的Object.keys():
const _makeQueue = (preparedSchema, originalSchema) => {
const queue = [];
(function scoped(obj, acc = []) {
if (/__sjs/.test(obj)) {
// ...
}
return Object
.keys(obj)
.map(prop => scoped(obj[prop], [...acc, prop]));
})(preparedSchema);
return queue;
};scoped函数开始执行的时候,首先是一个if判断,刚开始obj就是preparedSchema,是一个对象,那么正则表达式的test函数接受一个对象做为参数做了什么呢?
因为test函数的含义就是测试一个字符串是否满足正则表达式,当遇到非字符串参数的时候,会首先把参数转化为字符串,所以给test传入preparedSchema的时候,首先调用了对象的toString方法,普通对象调用toString方法一般返回[object Object]:
/__sjs/.test({name: 'hello'}) // false
/\[object Object\]/.test({name: 'hello'}) // truescoped函数刚开始执行的时候if判断失败,会走到Object.keys。同理,如果遇到嵌套的对象,就像上面这个例子,当分析到属性c的值的时候,也会使用Object.keys遍历里面的d和e属性,同时acc变量会把当前访问路径加进去。
不过,如果定义的时候没有使用attr属性,就有可能会导致堆栈溢出:
// 没有按照规范定义schema
var schema = {
a: 'string',
b: attr('string')
}在_prepare方法里面JSON.stringify的时候,我们直接使用的'string'在!value.isSJS这个判断中成功,所以直接返回了value:
const _prepare = (schema) => {
const preparedString = JSON.stringify(schema, (_, value) => {
if (!value.isSJS) return value;
// ...
});
// ...
};所以_prepare返回值里面的preparedSchema如下:
{a: "string", b: "string__sjs"}接下来执行_makeQueue的时候,当完成preparedSchema处理之后,会开始处理属性a的属性值,也就是scoped('string', ['a']),首先if判断是失败的,执行Object.keys('string'):
Object.keys('string') // ["0", "1", "2", "3", "4", "5"]
Object.keys('hello') // ["0", "1", "2", "3", "4"]
Object.keys(123) // []
Object.keys(true) // []这里隐藏着另外一个知识点:Object.keys会首先把参数转换成对象,也就是new String('string')
我们接着往下看,
Object.keys('string').map(prop => scoped(obj[prop], [...acc, prop])map的时候prop就是0,1,2,3,4,5,obj[prop]就是每个字符,所以会进入scoped('s', ['a', '0']), scoped('t', ['a', '1']) ...。
看第一个scoped('s', ['a', '0']),就会进入和上面一样的分析过程,只不过原先的参数'string'变成了's',所以会进入到scoped('s', ['a', '0', '0']),然后再进入到scoped('s', ['a', '0', '0', '0']) ...,直到堆栈溢出。
例子二:属性值undefined
var schema = {
a: attr('string'),
b: attr('number'),
c: attr('string')
}
// 需要stringify的对象
var obj = {
a: undefined,
b: undefined,
c: undefined
}我们前面讲过_makeChunks是用来提取stringify后的字符串里面不变的部分的,简化版本删除了和属性值是undefined相关的代码,我们现在来看下:
const _makeChunks = (str, queue) => str
.replace(/"\w+__sjs"/gm, type => (/string/.test(type) ? '"__par__"' : '__par__'))
.split('__par__')
.map((chunk, index, chunks) => {
const matchProp = `("${(queue[index] || {}).name}":(\"?))$`;
const matchWhenLast = `(\,?)${matchProp}`;
const isLast = /^("}|})/.test(chunks[index + 1] || '');
const matchPropRe = new RegExp(isLast ? matchWhenLast : matchProp);
const matchStartRe = /^(\"\,|\,|\")/;
return {
flag: false, // 表明前面的属性值是不是undefined
pure: chunk,
// Without initial part
prevUndef: chunk.replace(matchStartRe, ''),
// Without property chars
isUndef: chunk.replace(matchPropRe, ''),
// Only remaining chars (can be zero chars)
bothUndef: chunk
.replace(matchStartRe, '')
.replace(matchPropRe, ''),
};
});queue参数就是前面_makeQueue方法生成的用于存放变的部分的相关信息。当属性值是undefined的时候,属性名也不会出现在最终的字符串中。但是我们生成的chunks是包含属性名的,所以需要用正则把属性名给删掉。
matchProp匹配的属性的键值部分,也就是"key":"或者"key":,后面这个引号是字符串类型的时候会有,其他类型的时候没有,和前面的replace方法对应。
matchWhenLast匹配当undefined的属性是这个对象最后一个属性的时候,这个属性前面的逗号也要去掉。
isLast是用于判断这个属性是不是对象的最后一个属性的,根据这个判断是用mathProp还是matchWhenLast。
matchPropRe就是根据前面isLast判断之后的最终的正则表达式。
matchStartRe是,当前面一个属性是undefined的时候,该静态字符串前面用于拼合前面属性的部分。
所以返回值里面的这几个属性分别表示:
- flag: 前面的属性值是不是undefined
- pure: 前面的属性值和该静态字符串后面的属性值都不是undefined的时候用这个原始静态字符串,我们简版里面就是使用的这个字段
- prevUndef: 只有前面的属性值是undefined的时候,用这个处理过后的静态字符串
- isUndef: 只有该静态字符串后面的属性值是undefined的时候,用这个处理过后的静态字符串
- bothUndef: 前面的属性值和该静态字符串后面的属性值都是undefined的时候,使用这个处理后的静态字符串
接下来分析_select方法,这几个字段是在_select中被消费的:
const _select = chunks => (value, index) => {
const chunk = chunks[index];
if (typeof value !== 'undefined') {
if (chunk.flag) {
return chunk.prevUndef + value; // 11
}
return chunk.pure + value; // 12
}
chunks[index + 1].flag = true; // 标记后面静态字符串前面的属性值是undefined
if (chunk.flag) {
return chunk.bothUndef; // 21
}
return chunk.isUndef; // 22
};- 11对应只有前面的属性值是undefined,所以使用了prevUndef
- 12对应前后属性值都不是undefined,所以使用了prue
- 21对应前后属性值都是undefined,所以使用了bothUndef
- 22对应只有后面的属性值是undefined,所以使用了isUndef
下面看下例子:
var schema = {
a: attr('string'),
b: attr('number'),
c: attr('string')
}
obj = {
a: undefined,
b: undefined,
c: undefined
}
sjs(schema)(obj) // "{}"
从上图中看出其实结果就是chunks[0].isUndef + chunks[1].bothUndef + chunks[2].bothUndef + chunks[3].prevUndef,所以最后的结果是"{}"。
再看下面的例子
obj = {
a: undefined,
b: 3,
c: undefined
}
sjs(schema)(obj) // "{"b":3}"
从上图中看出其实结果就是chunks[0].isUndef + chunks[1].prevUndef + 3 + chunks[2].isUndef + chunks[3].prevUndef,所以最后的结果是"{"b":3}"。
例子二:数组
var schema = {
a: attr('array', sjs({
b: attr('string'),
c: attr('number'),
}))
}
var obj = {
a: [
{
b: 'hello',
c: 1
},
{
b: 'hello',
c: 2
}
]
}
var stringify = sjs(schema)
stringify(obj) // "{"a":[{"b":"hello","c":1},{"b":"hello","c":2}]}"我们看下attr方法里面和数组类型相关的代码
const attr = (type, serializer) => {
// ...
return {
isSJS: true,
type,
serializer: type === 'array'
? _makeArraySerializer(serializer) // 数组类型,做特殊处理
: usedSerializer,
};
};看下_makeArraySerializer方法:
const _makeArraySerializer = (serializer) => {
if (serializer instanceof Function) {
return (array) => {
// Stringifying more complex array using the provided sjs schema
let acc = '';
const { length } = array;
for (let i = 0; i < length - 1; i++) {
acc += `${serializer(array[i])},`;
}
// Prevent slice for removing unnecessary comma.
acc += serializer(array[length - 1]);
return `[${acc}]`;
};
}
return array => JSON.stringify(array);
};从上述代码可以发现,如果没有定义可以的序列化方法,会直接调用JSON.stringify方法,也就是我们的schema可以直接写成:
var schema = {
a: attr('array')
}
sjs(schema)(obj) // {"a":[{"b":"hello","c":1},{"b":"hello","c":2}]}但是这种stringify字符串的时候还是使用原生的JSON.stringify方法。
当定义了可用的数组序列化方法的时候,我们会发现其实这个方法是用来stringify每一项的方法,所以数组的序列化方法要做的就是:
把数组的每一项使用序列化方法调用一下,然后把结果拼成数组的形式。需要拼凑的部分包括前后的[]以及每项之间的分割符,。
这段代码遍历前面length - 1个元素,每个元素后面拼上逗号,最后再拼上最后一个数据项。但是,拼上最有一个数据项的时候没有做任何判断,如果数组长度是0也会拼上一项,所以导致最后的结果是多一个{}:
var schema = {
a: attr('array', sjs({
b: attr('string'),
c: attr('number'),
}))
}
var obj = {
a: []
}
var stringify = sjs(schema)
stringify(obj) // "{"a":[{}]}"
var schema = {
a: attr('array')
}
var stringify = sjs(schema)
stringify(obj) // "{"a":[]}"
JSON.stringify(obj) // "{"a":[]}"结语
本文到这里就结束了,与君共勉。
来自:https://segmentfault.com/a/1190000037530424
Js中的 forEach 源码
在日常 Coding 中,码农们肯定少不了对数组的操作,其中很常用的一个操作就是对数组进行遍历,查看数组中的元素,然后一顿操作猛如虎。今天暂且简单地说说在 JavaScript 中 forEach。
微信小程序代码源码案例大全
克隆项目代码到本地(git应该都要会哈,现在源码几乎都会放github上,会git才方便,不会的可以自学一下哦,不会的也没关系,gitHub上也提供直接下载的链接);打开微信开发者工具;
Node 集群源码初探
随着这些模块逐渐完善, Nodejs 在服务端的使用场景也越来越丰富,如果你仅仅是因为JS 这个后缀而注意到它的话, 那么我希望你能暂停脚步,好好了解一下这门年轻的语言,相信它会给你带来惊喜
Vue源码之实例方法
在 Vue 内部,有一段这样的代码:上面5个函数的作用是在Vue的原型上面挂载方法。initMixin 函数;可以看到在 initMixin 方法中,实现了一系列的初始化操作,包括生命周期流程以及响应式系统流程的启动
vue源码解析:nextTick
nextTick的使用:vue中dom的更像并不是实时的,当数据改变后,vue会把渲染watcher添加到异步队列,异步执行,同步代码执行完成后再统一修改dom,我们看下面的代码。
React源码解析之ReactDOM.render()
React更新的方式有三种:(1)ReactDOM.render() || hydrate(ReactDOMServer渲染)(2)setState(3)forceUpdate;接下来,我们就来看下ReactDOM.render()源码
React源码解析之ExpirationTime
在React中,为防止某个update因为优先级的原因一直被打断而未能执行。React会设置一个ExpirationTime,当时间到了ExpirationTime的时候,如果某个update还未执行的话,React将会强制执行该update,这就是ExpirationTime的作用。
扒开V8引擎的源码,我找到了你们想要的前端算法
算法对于前端工程师来说总有一层神秘色彩,这篇文章通过解读V8源码,带你探索 Array.prototype.sort 函数下的算法实现。来,先把你用过的和听说过的排序算法都列出来:

jQuery源码之extend的实现
extend是jQuery中一个比较核心的代码,如果有查看jQuery的源码的话,就会发现jQuery在多处调用了extend方法。作用:对任意对象进行扩;’扩展某个实例对象
vuex源码:state及strict属性
state也就是vuex里的值,也即是整个vuex的状态,而strict和state的设置有关,如果设置strict为true,那么不能直接修改state里的值,只能通过mutation来设置
内容以共享、参考、研究为目的,不存在任何商业目的。其版权属原作者所有,如有侵权或违规,请与小编联系!情况属实本人将予以删除!