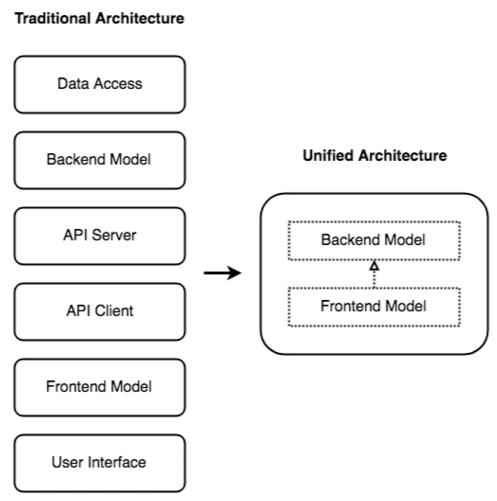
现代的全栈应用程序通常由六层组成:数据访问、后端模型、api 服务端、API 客户端、前端模型和用户界面。我们需要大量的胶水代码才能将它们全部连接起来,并且领域模型在整个栈中存在重复。因此,开发的敏捷性受到了极大的影响。本文如何使用统一架构来构建全栈应用程序,以及统一架构语言扩展 Liaison。
现代的全栈应用程序(例如,单页应用程序或移动应用程序)通常由六层组成:
- 数据访问
- 后端模型
- API 服务端
- API 客户端
- 前端模型
- 用户界面
通过这种架构方式,我们可以实现某些设计良好的应用程序特性,例如 关注点分离(separation of concerns,SoC) 或 松 散 耦合(loose coupling) 。
但它也并非没有缺点。它通常是以牺牲其他一些重要特性为代价的,比如简单性、 内聚性 或敏捷性。
似乎我们不可能拥有上述全部特性。我们必须妥协。
但问题在于,通常每一层都是作为一个完全不同的世界被单独构建的。
即使这些层都是使用相同的语言实现的,它们之间也不能很容易地通信和共享。
我们需要大量的 胶水代码 才能将它们全部连接起来,并且 领域模型 重复地存在于整个栈中。因此,开发的敏捷性受到了极大的影响。
例如,向模型中添加一个简单的字段通常需要修改栈中的所有层。难道您不觉得这有点可笑吗?
最近我一直在思考这个问题,我相信我已经找到了解决的办法。
诀窍在于:当然,应用程序的层必须是“物理上”的分割,但不需要是“逻辑上”的分割。
统一架构
在面向对象编程中,当我们使用继承时,我们可以得到一些类,并从两种角度来观察它们:物理和逻辑。这是什么意思呢?
假设我们有一个继承自 A 类的 B 类,那么,可以将 A 和 B 看作是两个物理类。但是在逻辑上,它们并不是分离的,B 可以被看作是一个逻辑类,它是由 A 的属性和其自身的属性组成的。
例如,当我们在类中调用某个方法时,我们不必担心这个方法是在这个类中实现的还是在它的父类中实现的。从调用方的角度来看,只需要担心一个类即可。父类和子类被统一成一个逻辑类了。
如何将相同的方式应用到应用程序的各个层中呢?例如,如果前端可以以某种方式从后端继承,这不是很好吗?
这样做,前端和后端将被统一到一个单一的逻辑层,这将消除所有通信和共享问题。实际上,可以从前端直接访问后端的类、属性和方法。
当然,我们通常不希望将整个后端都暴露给前端。但是类继承也是如此,并且它有一个优雅的解决方案叫做“私有属性”。类似地,后端也可以有选择地暴露一些属性和方法。
能够从一个统一的世界中掌握应用程序的所有层并不是一件小事。它完全改变了游戏规则。这就像是从三维世界降到二维世界。一切都变得容易多了。
继承并不邪恶 。是的,它可能被误用了,并且在某些语言中,它可能非常僵化。但是,如果使用得当,它会是我们的工具箱中的一种宝贵机制。
不过,我们有个问题。据我所知,没有一种语言允许我们可以跨多个执行环境继承类。但我们是程序员,不是吗?我们可以构建我们所需的一切,并且我们可以扩展语言来提供新的功能。
但在我们开始之前,让我们先对技术栈进行下分解,看看每层应该如何适用于统一架构。
数据访问
对于大多数应用程序,可以使用某种 ORM 来对数据库进行抽象。因此,从开发人员的角度来看,无需担心数据访问层。
对于更复杂的应用程序,我们可能必须优化数据库模式和请求。但我们不想因为这些问题而使后端模型变得混乱,因此此处可能需要额外附加一层。
我们构建一个数据访问层来实现优化关注点,而这通常发生在开发周期的后期(如果真的会发生的话)。
不管怎样,如果我们需要这样一个层,我们可以稍后再构建它。通过跨层继承,我们可以在后端模型层上再添加一个数据访问层,而这几乎不需要对现有代码进行任何更改。
后端模型
通常,后端模型层具有如下职责:
- 塑造领域模型。
- 实现业务逻辑。
- 处理授权机制。
对于大多数后端,最好在一个单一层中实现它的全部职责。但是,如果我们希望单独处理一些关注点,例如,如果我们希望将授权与业务逻辑分开,那么我们可以在两个相互继承的层中实现它们。
API 层
为了连接前端和后端,我们通常会构建一个 Web API(REST、GraphQL 等),这会使一切变得复杂。
Web API 必须在两侧都实现:前端是 API 客户端,后端是 API 服务端。这就是需要担心的两个额外层,并且它通常会导致需要复制整个领域模型的后果。
Web API 无非就是胶水代码,并且构建起来非常麻烦。所以,如果我们能避免,这将是一个巨大的进步。
幸运的是,我们可以再次利用跨层继承。在统一架构中,不需要构建 Web API。我们所要做的就是让前端模型从后端模型中继承,这样就完成了。
然而,仍然存在一些需要构建 Web API 的很好用例。这时,我们需要向某些第三方开发人员公开后端,或者需要与某些遗留的旧系统进行集成。
但是说实话,大多数应用程序都没有这样的需求。而当它们需要这样做时,事后处理也很容易。我们可以简单地将 Web API 实现到继承自后端模型层的新层中。
关于这个主题的更多信息可以在 这篇文章 中找到。
前端模型
因为后端是事实来源,所以它应该实现所有的业务逻辑,而前端不应该实现任何业务逻辑。因此,前端模型只是简单地继承自后端模型而已,几乎没有添加任何内容。
用户界面
我们通常是在两个独立的层中实现前端模型和 UI。但是,正如我在 这篇文章 中所展示的,它不是强制性的。
当前端模型由类构成时,可以将视图封装为简单的方法。如果您现在不明白我的意思,请不用担心,在后面的示例中我会给出更清楚解释。
由于前端模型基本上是空的(请参见上文),所以可以直接在其中实现 UI,因此技术栈本身就没有用户界面层了。
当我们想要支持多个平台(例如,Web 应用程序和移动应用程序)时,仍然需要在单独的层中实现 UI。但是,由于这只是继承一个层的问题,所以可以在开发路线图的后期进行。
将一切组装起来
统一架构使我们能够将 6 个物理层统一为 1 个逻辑层:
- 在最小的实现中,数据访问被封装到了后端模型中,UI 也被封装到了前端模型中。
- 前端模型继承自后端模型。
- 不再需要 API 层。
结果如下图所示:
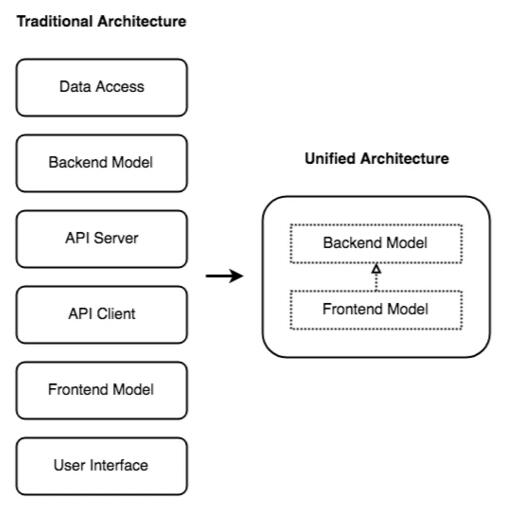
真是太壮观了,您不觉得吗?
Liaison
为了实现一个统一的架构,我们所需的只是跨层继承,而我是通过构建 Liaison 来实现这一点的。
如果您愿意的话,可以把 Liaison 看作一个框架,但是我更喜欢把它描述成一个语言扩展,因为它的所有特性都位于尽可能低的级别上:编程语言级别。
所以,Liaison 并不会把您锁定在一个预定义的框架中,而是可以在其之上创建一个完整的宇宙。您可以在 这篇文章 中阅读到更多关于此主题的信息。
在后台,Liaison 依赖于 RPC 机制。因此,从表面上看,它可以被看作是 CORBA 、 Java RMI 或 .NET CWF 之类的东西。
但是 Liaison 是完全不同的:
- 它不是一个 分布式对象系统 。实际上,Liaison 的后端是无状态的,因此没有跨层的共享对象。
- 它是在语言级别实现的(见上文)
- 它的设计简单明了,并且公开了最少的 API。
- 它不涉及任何样板代码、生成的代码、配置文件或工件。
- 它使用了一个简单但功能强大的序列化协议( Deepr ),该协议支持一些独特的特性,比如链式调用、自动化批处理或部分执行。
Liaison 始于 JavaScript,但是它所解决的问题是通用的,并且可以将它移植到任何面向对象的语言中而不会带来太多的麻烦。
Hello 计数器
让我们通过将经典的“计数器”示例实现成一个单页应用程序来说明 Liaison 是如何工作的吧。
首先,我们需要在前端和后端之间共享一些代码:
// shared.js
import{Model, field} from '@liaison/liaison';
exportclassCounterextendsModel{
// 共享类定义一个字段来跟踪计数器的值
@field('number') value =0;
}
然后,构建后端以实现业务逻辑:
// backend.js
import{Layer, expose} from '@liaison/liaison';
import{CounterasBaseCounter} from './shared';
classCounterextendsBaseCounter{
// 我们将“value”字段暴露给前端
@expose({get:true, set:true}) value;
// 我同样将 increment() 方法暴露给前端
@expose({call:true}) increment() {
this.value++;
}
}
// 我们将后端类注册到导出层中
export const backendLayer =newLayer({Counter});
最后,让我们来构建前端:
// frontend.js
import{Layer}from'@liaison/liaison';
import{CounterasBaseCounter}from'./shared';
import{backendLayer}from'./backend';
classCounterextendsBaseCounter{
// 目前,前端类只是继承共享类
}
// 我们将前端类注册到一个继承自后端层的层中
constfrontendLayer =newLayer({Counter}, {parent: backendLayer});
// 最后,我们实例化一个计数器
constcounter =newfrontendLayer.Counter();
// 运行计数器
awaitcounter.increment();
console.log(counter.value);// => 1
这是怎么回事呢?通过调用 counter.increment(),我们可以使计数器的值递增。请注意,increment() 方法既没有在前端类中实现,也没有在共享类中实现。它只存在于后端。
那么,我们为什么能从前端调用它呢?这是因为前端类注册在从后端层继承的层中。因此,当前端类中缺少某个方法,而后端类中公开了具有相同名称的方法时,则会自动调用该方法。
从前端的角度来看,该操作是透明的。它不需要知道哪个方法被远程调用了。它只是调用。
实例的当前状态(即,counter 的属性)会被自动地来回传输。当方法在后端执行时,将发送在前端修改的属性。相反,当某些属性在后端发生变化时,它们也会反映到前端。
注意,在这个简单的示例中,后端并不是完全远程的。前端和后端都在同一个 JavaScript 运行时中运行。为了使后端真正处于远程状态,我们可以通过 HTTP 轻松地公开它。请看 此处 的示例。
如何向(从)远程调用的方法传递(返回)值呢?可以传递(返回)任何可序列化的内容,包括类实例。只要在前端和后端使用相同的名称注册一个类,就可以自动传输它的实例。
如何跨前端和后端重写一个方法呢?这与常规的 JavaScript 没有什么不同,我们可以使用 super。例如,我们可以重写 increment() 方法以在前端的上下文中运行额外的代码:
// frontend.js
classCounterextendsBaseCounter{
async increment() {
awaitsuper.increment();// 后端的`increment()` 方法被调用
console.log(this.value);// 在前端添加额外的运行代码
}
}
现在,让我们使用 React 和前面所示的封装方法构建一个用户界面:
// frontend.js
importreactfrom'react';
import{view} from '@liaison/react-integration';
classCounterextendsBaseCounter{
// 我们使用`@view()`装饰器来观察模型,并在需要时重新渲染视图
@view()View() {
return(
<div>
{this.value} <button onClick={() =>this.increment()}>+</button>
</div>
);
}
}
最后,为了显示计数器,我们需要的是:
<counter.View />
瞧!我们构建了一个具有两个统一层和一个封装 UI 的单页应用程序。
概念验证
为了试验统一架构,我使用 Liaison 构建了一个 RealWorld 示例应用程序 。
我可能有些自夸了,但结果看起来真的非常惊人:实现简单,代码高内聚,100% DRY (Don’t repeat yourself),没有胶水代码。
就代码量而言,我的实现比我使用过的其他任何实现都要轻得多。 点击这里 查看结果。
当然,RealWorld 示例是一个小型应用程序,但是由于它涵盖了所有应用程序都共有的最重要的概念,因此我相信统一架构可以扩展到更复杂的应用程序中。
结论
关注点分离、松散耦合、简单性、内聚性和敏捷性。
似乎这一切都实现了。
如果您是一位经验丰富的开发人员,那么我想您对此会有所怀疑,这也很正常。我们很难把多年的习惯抛诸脑后。
如果您不喜欢面向对象编程,那么就不要使用 Liaison 了,这也是完全没有问题的。
但是,如果您对 OOP 感兴趣,请在脑海中打开一扇小窗,下一次您必须构建一个全栈应用程序时,请试试看它是如何适用于统一架构的。
Liaison 仍处于早期阶段,但我正在积极研究中,我希望在 2020 年初发布第一个测试版本。
如果您有兴趣的话,请为 代码库 加注star 标,并通过关注 博客 或订阅 newsletter 的方式来保持更新。
如果这篇文章对您有帮助,您可以或者。
原文链接:https://www.freecodecamp.org/news/full-stack-unified-architecture/
阿里P7详谈“全栈”概念
前端程序员看到“全栈”这个概念,大概会有两种反应:1. 卧槽,这个好,碉堡了,2. 你懂毛,全栈就是样样稀松。即使只学一门技术,水平很菜的人也多的是,而全栈工程师当中样样都做,而样样都做得不错的也不少。
前端、后端和全栈到底不该学什么?
很多人为了成为全栈工程师或者已经是全栈工程师面对着巨大的困境。1.一个工作两年的切图都比一个全栈工程师切图好,一个8k的java都比3W的全栈写的代码快,他们经历着博而不精的煎熬。2.成为全栈很多人需要花费大量的学习时间,到最后依然是无功而返。
web全栈开发工程师的趋势、价值
随着技术的发展、用户量的增加、客户端种类变多,每一个小小的细节都需要优化和考虑。在海量的访问量面前,也许改变一个按钮的位置和颜色就能影响上千万次的用户体验
全栈开发者意味着什么?
最近,在我参加的一个Web技术会议上,一位开发同事问了我这个问题。这位开发同事遇到的很多新人都自称是全栈开发人员,有点像Bob自称是Tony的意味,名不副实。本文以这位开发同事提的问题作为标题

16 岁的我是如何成为全栈开发人员的?
故事要从我 14 岁那会说起。当时的我学过 PHP、HTML/CSS 和 JavaScript,而且对自己的朋友充满嫉妒。作为在网上发布的第一篇“严肃”文章,我想从自己的成长经历谈起——当然,之后我还会更新更多文章,毕竟学无止境嘛
内容以共享、参考、研究为目的,不存在任何商业目的。其版权属原作者所有,如有侵权或违规,请与小编联系!情况属实本人将予以删除!