在分布式系统中,会经常用到K-V存储,一般实现的方式有红黑树或者哈希表,在Redis中还用到了跳表。都是通过一个确定的Key值,来查找Key附带的Value属性。本文会介绍一种高效的算法——多阶Hash。
1原理
多阶Hash的实现原理很简单,每个Hash桶数组算作一阶,如果有20阶的多阶Hash,那么就是一个二维数组,第一维是Hash桶的编号,第二维是每个Hash桶的每个槽的位置。实际开发中,可以申请一块连续的内存,由一维数组构造出二维数组。内存构造如下图所示,逻辑上是一个阶梯状,实际申请内存,是一块连续的内存结构,用每次层的阶数来标识出不同阶的分界。如下图所示:
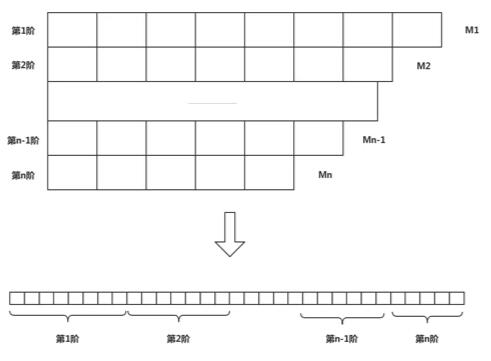
通常每阶的槽的个数都是质数个,每阶的槽的个数依次递减。由于互质的特性,通常情况下会上面的阶数先被填满,然后再逐步填下面的阶数。在实际使用中,内存使用率可以达到90%以上。
查找和修改的时间复杂度都是 O(h) ,h是阶数。
与教科书中的开链Hash对比,优缺点如下:
2优点
1、查找时间稳定
查找时间和阶数成正比,虽然不一定最高效,但是是可控的,最坏要多少次查找是能够控制的。如果是接链表解决冲突,冲突太多就退化成链表操作,耗时不可控。
2、实现简单
实现完全是数组操作,而且存储内容都是定长。与树形数据结构相比,实现简单很多。
3、方便序列化
由于底层是连续内存,能够通过内存迭代遍历全部元素,dump到外部文件。再通过dump文件重新插入实现恢复数据。
4、鲁棒性强
互联网业务大都是常驻进程,如果进程重启会导致栈或堆中的内存销毁。可以通过共享内存来达到重启后恢复内存数据。由于多阶Hash底层是数组结构,只需要知道起始位置和元素下标,就能够对内存元素进行操作。进程重启后重新挂载内存即可恢复操作,不需要重建索引。
3缺点
1、容量有限
由于阶数有限,如果最后一阶填满后,会导致Key值没有地方存储。不如链表的扩展性好。
在实际项目,要做好容量管理和监控。当发现使用率超过70%的时候,就要准备扩容,防止写满。
2、存储定长
存储的部分是二维数组的Hash桶的块,是一块定长的内存。如果存储的数据是变长的,就需要把内存块定义为最大Value的长度,会造成内存浪费。常见优化方法是在Hash块中存储一个索引,索引指向另外一块内存链表,变长数据被分别存储在多个内存链表中。一般设置每块内存链表的长度也需要计算。
多阶Hash适用于读多写少的互联网业务场景,通常是一个进程负责写操作,多个进程负责读操作。多个进程来提高整体的读的并发量,来弥补每次查找都需要 O(h) 的复杂度。
多阶Hash是一种在生产实践中总结的算法,从学术上看它并不完美。因为会出现元素存不下的情况,而且时间复杂度的常数系数比较大。但是在互联网读多写少的业务场景中,读速度可控,容量管理能监控,这些问题都能够被解决。同时还带来容易实现,鲁棒性强,内存使用率高的优点。
在实践中得到的这个算法,虽然不是十分优美,但是真的十分实用。
原文 https://www.owenzhang.net/blog/330.html
关于Webpack中hash的用法
在webpack的配置项中,可能会见到hash这样的字符。这种带哈希值的文件名,可以帮助实现静态资源的长期缓存,在生产环境中非常有用。带hash的文件是现在web启用缓存来提升性能比较建议的形式。
location.hash属性#_window.location.hash 使用
hash 属性是一个可读可写的字符串,该字符串是 URL 的锚部分(从 # 号开始的部分),#是用来指导浏览器动作的,都会被浏览器解读为位置标识符 , 这意味着这些字符都不会被发送到服务器端。对服务器端完全无用。所以,HTTP请求中不包括#。
vue-router之hash模式和history模式
hash模式即地址栏 URL 中的 # 符号(此 hash 不是密码学里的散列运算)。history模式利用了 HTML5 History Interface 中新增的 pushState() 和 replaceState() 方法。
一致性hash算法和实现
一致性hash算法,是麻省理工学院1997年提出的一种算法,目前主要应用于分布式缓存当中。一致性hash算法可以有效地解决分布式存储结构下动态增加和删除节点所带来的问题。
webpack打包的3种hash值区别
我们都知道,webpack有各种hash值,包括每次项目构建hash,不同入口的chunkhash、文件的内容contenthash,这么多hash,它们有什么区别呢?
vue-router的两种模式:hash和history详解
Vue.js是一种流行的JavaScript框架,用于构建交互式Web应用程序。Vue-router是Vue.js框架中的一个重要组件,它允许您为应用程序创建路由。在Vue-router中,有两种不同的路由模式:hash模式和history模式
内容以共享、参考、研究为目的,不存在任何商业目的。其版权属原作者所有,如有侵权或违规,请与小编联系!情况属实本人将予以删除!