猿类创造的原始动力多来源于偷懒
前端的同学们在搭建自己的开发环境的时候,为了避免手动刷新浏览器的繁复,使用起了热更新工具
browserSync 和 webpack-dev-server是其中的代表作品
一、websocket简介
在h5推出之前,浏览器应用跟服务器端通信的机制只有http协议,http是一种无状态的网络协议,前端向服务器发起一个请求,服务器给出一次应答,服务器无法主动向客户端发起通信,这种设计主要是为了节省带宽资源,客户端和服务器端不需要维持长连接
早期要实现一个浏览器即使通信工具(如webqq),由于服务器端不能主动向客户端发起通信,只能客户端设置一个定时器,定时向服务器端发起请求拉取消息,很显然,这种轮询的方式对性能来说是一把杀猪刀
h5很应景的推出了websocket,这给了web开发者另一种选择去应付纷繁复杂的场景。WebSocket 是一个独立的基于TCP的协议,前端和服务器端可以建立起一个长连接,客户端可以向服务器端推送消息,服务器也可以主动向客户端推送消息
本文不对websocket做太深入的说明,有兴趣可留下你的评论
二、热更新原理

热更新
浏览器的网页通过websocket协议与服务器建立起一个长连接,当服务器的css/js/html进行了修改的时候,服务器会向前端发送一个更新的消息,如果是css或者html发生了改变,网页执行js直接操作dom,局部刷新,如果是js发生了改变,只好刷新整个页面
js发生改变的时候,不太可能判断出对dom的局部影响,只能全局刷新
为何没有提到图片的更新,如果是在html或者css里修改了图片路径,那么更新html和css,只要图片路径没有错,那么就已经达到了更新图片的路径。如果是相同路径的图片进行了替换,这往往需要重启下服务
在简单的网页应用中,这一个过程可能仅仅是节省了手动刷新浏览器的繁琐,但是在负责的应用中,如果你在调试的部分需要从页面入口操作好几步才到达,例如:登录->列表->详情->弹出窗口,那么局部刷新将大大提高调试效率
三、实例剖析
如果你使用gulp构建的前端开发工作环境,想必对browserSync不会陌生,你明白它的工作方式么?
browserSync易于使用:
var bs = browserSync({
port: 5000, //服务端口
notify: false,
logPrefix: 'PSK',
server: {
baseDir: '_dev', //服务路径,也就是页面资源存放的路径
directory: true
},
open: false //需不需要自动打开浏览器
}, function() {
//启动后的回调
});
很容易想到,这开启了一个http服务,在浏览器输入localhost:5000/path就可以访问到页面,不知道有没有细心的观众在查看页面源码的时候发现多了点什么不是你写的东西
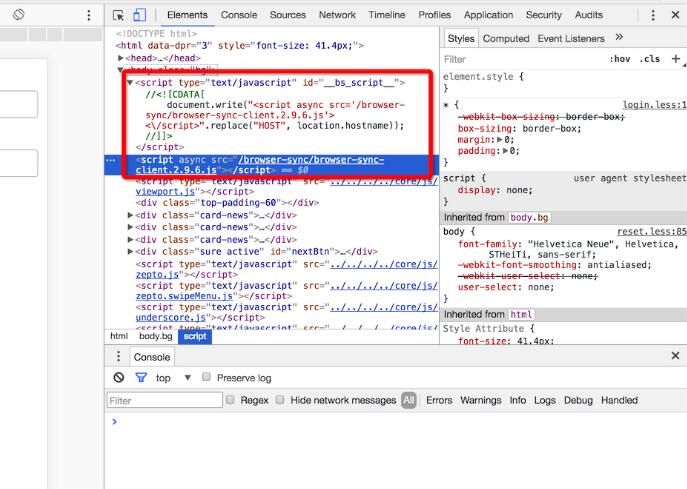
没错,browser-sync-client.2.9.6.js并不是你引入的,这个是browserSync在创建的时候,为你的html自动注入的(baseDir目录下),部分代码:
.........
___browserSync___.io = window.io;
window.io = window.___browserSync___oldSocketIo;
window.___browserSync___oldSocketIo=undefined;
___browserSync___.socketConfig = {"reconnectionAttempts":50,"path":"/browser-sync/socket.io"};
___browserSync___.socket = ___browserSync___.io('' + location.host + '/browser-sync', ___browserSync___.socketConfig);
"use strict";
(function (window, document, bs, undefined) {
var socket = bs.socket;
var uiOptions = {
bs: {}
};
..........
原谅我并未仔细研读过次文件代码,因为实在太多太凌乱,但是从上面这几行代码,以及文件名,就基本可以确定这是websocket-client的代码
读过的同学求抱大腿
下面再来做一个实验来确认下,control+c 把服务器关闭,再来看看刚才那网页的控制台:
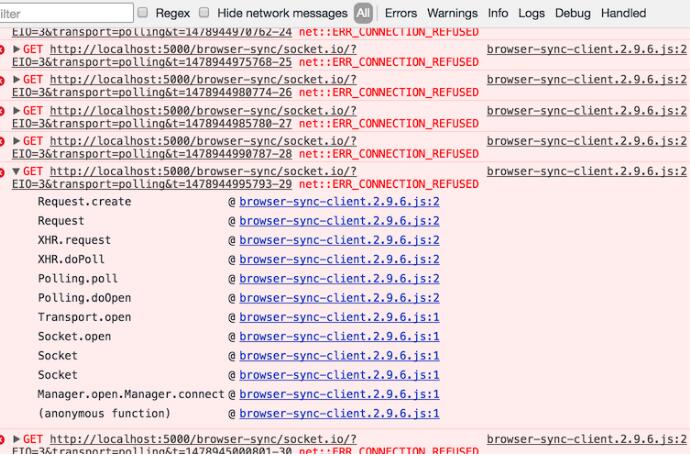
控制台一直在报错,why? 因为服务器关闭了之后,连接断开,客户端一直在尝试对服务器发起重连
再来看看webpack是怎么做的,webpack可以使用webpack-dev-server来搭建热跟新的开发环境,webpack-dev-server是基于express的轻量级服务器,作用有点类似于上述的browserSync,你需要在webpack.config.js中的entry配置里增加的点东西
var config = {
entry: ['webpack/hot/dev-server', './app/main.js'],
output: {
path: path.resolve(__dirname, './build'),
filename: 'bundle.js'
},
module: {
loaders: [{
test: /\.js$/,
// Use the property "loaders" instead of "loader" and
// add "react-hot" in front of your existing "jsx" loader
// 使用 "loaders" 属性代替 "loader"
// 然后在 "jsx" 加载器之前添加 "react-hot"
loaders: ['react-hot', 'babel']
}]
}
};
配置中增加了webpack/hot/dev-server实体,跟main.js一起打包成bundle.js,这个就可以类比到上面的browser-sync-client.2.9.6.js
如果自己搭建express,还可以使用webpack的热跟新中间件
四、总结
知其然并知其所以然是很重要的,不要求搞清楚每一个细节,但要懂得实现原理
前端开发,脱离菜鸟层次的二个关键点
我个人吧,一直认为学习前端技术是比较简单的事情,只要你真的是一步一个脚印的在前进,那你自然会有相应的结果可以收获。这里面包含二个关键点,一,脚踏实地;二,不断努力。
前端开发,如何写出优秀js代码
前端开发如何写出优秀js代码,什么样的javascript代码才是最优秀的的呢?我总结的大概分为三点:性能好,简单优雅,通俗易懂,这篇文章就将围绕这这3点来说明。
你不知道的前端SDK开发技巧
作为一个SDK,我们的目标是让使用者能够减少查看文档的时间,所以我们需要提供一些类型的检查和智能提示,一般我们的做法是提供JsDoc,大部分编辑器可以提供快捷生成JsDoc的方式,另一种做法是使用Flow或者TypeScript
Web前端体系的脉络结构
Web前端技术由 html、css 和 javascript 三大部分构成,是一个庞大而复杂的技术体系,其复杂程度不低于任何一门后端语言。
关于前端数据&逻辑的思考
这里我是基于典型的MVC模型,那么为了将现有代码重构为理想的模型,我需要做以下几步:拆分组件,逻辑处理,抽象、聚合数据

什么是前端? web1.0、web2.0时代的网页制作,前端开发都有哪些内容等
前端基础-什么是前端:一、 web1.0时代的网页制作,二、 web2.0时代的前端开发,三、 Web前端能做什么?四、 为什么要学习前端开发,五、 前端开发都有哪些内容,六、 开发环境
web前端的一些不为人知的冷知识点_html篇整理
web前端HTML篇冷知识点——这是一篇关于前端的技巧使用,或许你做前端很多年了,但是下面的这些你可能闻所未闻。现在这里给大家整理出来,分享给前端的小伙伴们。
web前端的一些不为人知的冷知识点_CSS篇整理
CSS篇整理:关于CSS的恶作剧、简单的文字模糊效果、垂直居中、多重边框、实时编辑CSS、创建长宽比固定的元素、CSS中也可以做简单运算
web前端的一些不为人知的冷知识点_Js篇整理
Js篇整理:生成随机字符串、整数的操作、重写原生浏览器方法以实现新功能、关于console的恶作剧、万物皆对象、If语句的变形、禁止别人以iframe加载你的页面、console.table
前后端分离后,后端应该知道的一些基本前端知识
作为前端小白,经常遇到同样小白的后端,常常不得不三番五次科普一些前端的基础知识,特此做些总结,前后端分离后,后端需要知道的基本前端知识:什么是ajax?跨域、OPTIONS请求、重定向等
内容以共享、参考、研究为目的,不存在任何商业目的。其版权属原作者所有,如有侵权或违规,请与小编联系!情况属实本人将予以删除!