前端框架的数据流
前端框架实现了数据驱动视图变化的功能,我们用 template 或者 jsx 描述好了数据和视图的绑定关系,然后就只需要关心数据的管理了。
数据在组件和组件之间、组件和全局 store 之间传递,叫做前端框架的数据流。
一般来说,除了某部分状态数据是只有某个组件关心的,我们会把状态数据放在组件内以外,业务数据、多个组件关心的状态数据都会放在 store 里面。组件从 store 中取数据,当交互的时候去通知 store 改变对应的数据。
这个 store 不一定是 redux、mobox 这些第三方库,其实 react 内置的 context 也可以作为 store。但是 context 做为 store 有一个问题,任何组件都能从 context 中取出数据来修改,那么当排查问题的时候就特别困难,因为并不知道是哪个组件把数据改坏的,也就是数据流不清晰。
正是因为这个原因,我们几乎见不到用 context 作为 store,基本都是搭配一个 redux。
所以为什么 redux 好呢?第一个原因就是数据流清晰,改变数据有统一的入口。
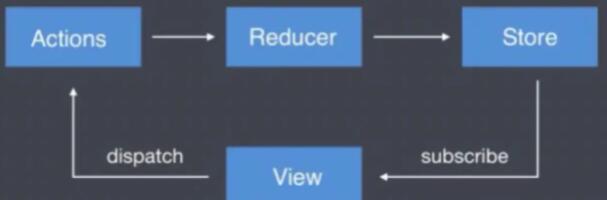
组件里都是通过 dispatch 一个 action 来触发 store 的修改,而且修改的逻辑都是在 reducer 里面,组件再监听 store 的数据变化,从中取出最新的数据。
这样数据流动是单向的,清晰的,很容易管理。
这就像为什么我们在公司里想要什么权限都要走审批流,而不是直接找某人,一样的道理。集中管理流程比较清晰,而且还可以追溯。
异步过程的管理
很多情况下改变 store 数据都是一个异步的过程,比如等待网络请求返回数据、定时改变数据、等待某个事件来改变数据等,那这些异步过程的代码放在哪里呢?
组件?
放在组件里是可以,但是异步过程怎么跨组件复用?多个异步过程之间怎么做串行、并行等控制?
所以当异步过程比较多,而且异步过程与异步过程之间也不独立,有串行、并行、甚至更复杂的关系的时候,直接把异步逻辑放组件内不行。
不放组件内,那放哪呢?
redux 提供的中间件机制是不是可以用来放这些异步过程呢?
redux 中间件
先看下什么是 redux 中间件:
redux 的流程很简单,就是 dispatch 一个 action 到 store, reducer 来处理 action。那么如果想在到达 store 之前多做一些处理呢?在哪里加?
改造 dispatch!中间件的原理就是层层包装 dispatch。
下面是 applyMiddleware 的源码,可以看到 applyMiddleware 就是对 store.dispatch 做了层层包装,最后返回修改了 dispatch 之后的 store。
function applyMiddleware(middlewares) {
let dispatch = store.dispatch
middlewares.forEach(middleware =>
dispatch = middleware(store)(dispatch)
)
return { ...store, dispatch}
}
所以说中间件最终返回的函数就是处理 action 的 dispatch:
function middlewareXxx(store) {
return function (next) {
return function (action) {
// xx
};
};
};
}
中间件会包装 dispatch,而 dispatch 就是把 action 传给 store 的,所以中间件自然可以拿到 action、拿到 store,还有被包装的 dispatch,也就是 next。
比如 redux-thunk 中间件的实现:
function createThunkMiddleware(extraArgument) {
return ({ dispatch, getState }) => next => action => {
if (typeof action === 'function') {
return action(dispatch, getState, extraArgument);
}
return next(action);
};
}
const thunk = createThunkMiddleware();
它判断了如果 action 是一个函数,就执行该函数,并且把 store.dispath 和 store.getState 传进去,否则传给内层的 dispatch。
通过 redux-thunk 中间件,我们可以把异步过程通过函数的形式放在 dispatch 的参数里:
const login = (userName) => (dispatch) => {
dispatch({ type: 'loginStart' })
request.post('/api/login', { data: userName }, () => {
dispatch({ type: 'loginSuccess', payload: userName })
})
}
store.dispatch(login('guang'))
但是这样解决了组件里的异步过程不好复用、多个异步过程之间不好做并行、串行等控制的问题了么?
没有,这段逻辑依然是在组件里写,只不过移到了 dispatch 里,也没有提供多个异步过程的管理机制。
解决这个问题,需要用 redux-saga 或 redux-observable 中间件。
redux-saga
redux-saga 并没有改变 action,它会把 action 透传给 store,只是多加了一条异步过程的处理。
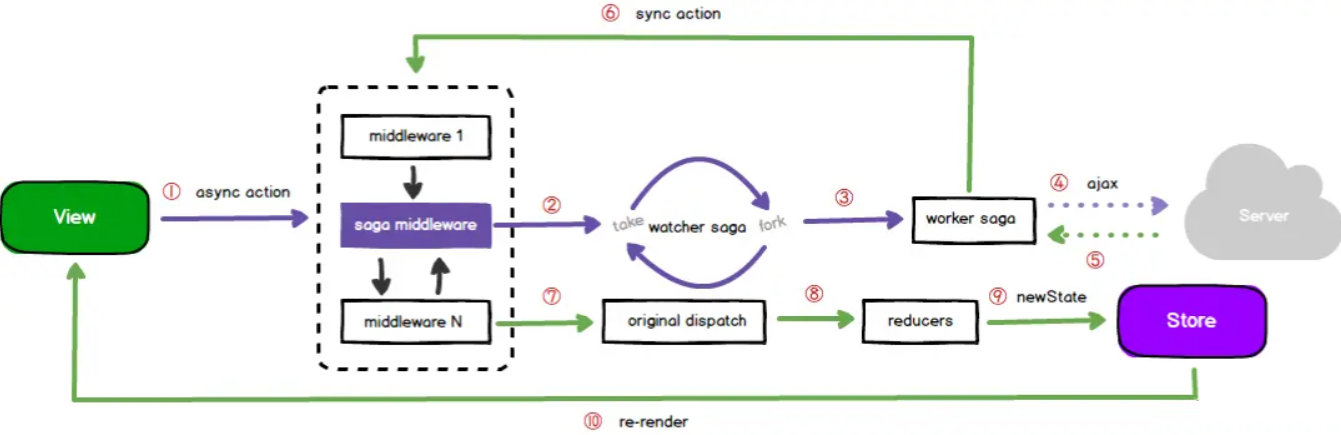
redux-saga 中间件是这样启用的:
import { createStore, applyMiddleware } from 'redux'
import createSagaMiddleware from 'redux-saga'
import rootReducer from './reducer'
import rootSaga from './sagas'
const sagaMiddleware = createSagaMiddleware()
const store = createStore(rootReducer, {}, applyMiddleware(sagaMiddleware))
sagaMiddleware.run(rootSaga)
要调用 run 把 saga 的 watcher saga 跑起来:
watcher saga 里面监听了一些 action,然后调用 worker saga 来处理:
import { all, takeLatest } from 'redux-saga/effects'
function* rootSaga() {
yield all([
takeLatest('login', login),
takeLatest('logout', logout)
])
}
export default rootSaga
redux-saga 会先把 action 透传给 store,然后判断下该 action 是否是被 taker 监听的:
function sagaMiddleware({ getState, dispatch }) {
return function (next) {
return function (action) {
const result = next(action);// 把 action 透传给 store
channel.put(action); //触发 saga 的 action 监听流程
return result;
}
}
}
当发现该 action 是被监听的,那么就执行相应的 taker,调用 worker saga 来处理:
function* login(action) {
try {
const loginInfo = yield call(loginService, action.account)
yield put({ type: 'loginSuccess', loginInfo })
} catch (error) {
yield put({ type: 'loginError', error })
}
}
function* logout() {
yield put({ type: 'logoutSuccess'})
}
比如 login 和 logout 会有不同的 worker saga。
login 会请求 login 接口,然后触发 loginSuccess 或者 loginError 的 action。
logout 会触发 logoutSuccess 的 action。
redux saga 的异步过程管理就是这样的:先把 action 透传给 store,然后判断 action 是否是被 taker 监听的,如果是,则调用对应的 worker saga 进行处理。
redux saga 在 redux 的 action 流程之外,加了一条监听 action 的异步处理的流程。
其实整个流程还是比较容易理解的。理解成本高一点的就是 generator 的写法了:
比如下面这段代码:
function* xxxSaga() {
while(true) {
yield take('xxx_action');
//...
}
}
它就是对每一个监听到的 xxx_action 做同样的处理的意思,相当于 takeEvery:
function* xxxSaga() {
yield takeEvery('xxx_action');
//...
}
但是因为有一个 while(true),很多同学就不理解了,这不是死循环了么?
不是的。generator 执行后返回的是一个 iterator,需要另外一个程序调用 next 方法才会继续执行。所以怎么执行、是否继续执行都是由另一个程序控制的。
在 redux-saga 里面,控制 worker saga 执行的程序叫做 task。worker saga 只是告诉了 task 应该做什么处理,通过 call、fork、put 这些命令(这些命令叫做 effect)。
然后 task 会调用不同的实现函数来执行该 worker saga。
为什么要这样设计呢?直接执行不就行了,为啥要拆成 worker saga 和 task 两部分,这样理解成本不就高了么?
确实,设计成 generator 的形式会增加理解成本,但是换来的是可测试性。因为各种副作用,比如网络请求、dispatch action 到 store 等等,都变成了 call、put 等 effect,由 task 部分控制执行。那么具体怎么执行的就可以随意的切换了,这样测试的时候只需要模拟传入对应的数据,就可以测试 worker saga 了。
redux saga 设计成 generator 的形式是一种学习成本和可测试性的权衡。
还记得 redux-thunk 有啥问题么?多个异步过程之间的并行、串行的复杂关系没法处理。那 redux-saga 是怎么解决的呢?
redux-saga 提供了 all、race、takeEvery、takeLatest 等 effect 来指定多个异步过程的关系:
比如 takeEvery 会对多个 action 的每一个做同样的处理,takeLatest 会对多个 action 的最后一个做处理,race 会只返回最快的那个异步过程的结果,等等。
这些控制多个异步过程之间关系的 effect 正是 redux-thunk 所没有的,也是复杂异步过程的管理必不可少的部分。
所以 redux-saga 可以做复杂异步过程的管理,而且具有很好的可测试性。
其实异步过程的管理,最出名的是 rxjs,而 redux-observable 就是基于 rxjs 实现的,它也是一种复杂异步过程管理的方案。
redux-observable
redux-observable 用起来和 redux-saga 特别像,比如启用插件的部分:
const epicMiddleware = createEpicMiddleware();
const store = createStore(
rootReducer,
applyMiddleware(epicMiddleware)
);
epicMiddleware.run(rootEpic);
和 redux saga 的启动流程是一样的,只是不叫 saga 而叫 epic。
但是对异步过程的处理,redux saga 是自己提供了一些 effect,而 redux-observable 是利用了 rxjs 的 operator:
import { ajax } from 'rxjs/ajax';
const fetchUserEpic = (action$, state$) => action$.pipe(
ofType('FETCH_USER'),
mergeMap(({ payload }) => ajax.getJSON(`/api/users/${payload}`).pipe(
map(response => ({
type: 'FETCH_USER_FULFILLED',
payload: response
}))
)
);
通过 ofType 来指定监听的 action,处理结束返回 action 传递给 store。
相比 redux-saga 来说,redux-observable 支持的异步过程的处理更丰富,直接对接了 operator 的生态,是开放的,而 redux-saga 则只是提供了内置的几个 effect 来处理。
所以做特别复杂的异步流程处理的时候,redux-observable 能够利用 rxjs 的操作符的优势会更明显。
但是 redux-saga 的优点还有基于 generator 的良好的可测试性,而且大多数场景下,redux-saga 提供的异步过程的处理能力就足够了,所以相对来说,redux-saga 用的更多一些。
总结
前端框架实现了数据到视图的绑定,我们只需要关心数据流就可以了。
相比 context 的混乱的数据流,redux 的 view -> action -> store -> view 的单向数据流更清晰且容易管理。
前端代码中有很多异步过程,这些异步过程之间可能有串行、并行甚至更复杂的关系,放在组件里并不好管理,可以放在 redux 的中间件里。
redux 的中间件就是对 dispatch 的层层包装,比如 redux-thunk 就是判断了下 action 是 function 就执行下,否则就是继续 dispatch。
redux-thunk 并没有提供多个异步过程管理的机制,复杂异步过程的管理还是得用 redux-saga 或者 redux-observable。
redux-saga 透传了 action 到 store,并且监听 action 执行相应的异步过程。异步过程的描述使用 generator 的形式,好处是可测试性。比如通过 take、takeEvery、takeLatest 来监听 action,然后执行 worker saga。worker saga 可以用 put、call、fork 等 effect 来描述不同的副作用,由 task 负责执行。
redux-observable 同样监听了 action 执行相应的异步过程,但是是基于 rxjs 的 operator,相比 saga 来说,异步过程的管理功能更强大。
不管是 redux-saga 通过 generator 来组织异步过程,通过内置 effect 来处理多个异步过程之间的关系,还是 redux-observable 通过 rxjs 的 operator 来组织异步过程和多个异步过程之间的关系。它们都解决了复杂异步过程的处理的问题,可以根据场景的复杂度灵活选用。
React项目实战:react-redux-router基本原理
React项目实战:react-redux-router基本原理,Redux 的 React 绑定库包含了 容器组件和展示组件相分离 的开发思想。明智的做法是只在最顶层组件(如路由操作)里使用 Redux。其余内部组件仅仅是展示性的,所有数据都通过 props 传入。
react关于 Redux与flux的比较学习
flux四大元素:Dispatcher:根据注册派发动作(action),Store: 存储数据,处理数据,Action:用于驱动Dispatcher,View: 用户界面视图。flux的目的:纠正MVC框架的无法禁绝view与model通信的缺点。Redux基本原则:继承Flux基本原则:单向数据流
如何优雅地在React项目中使用Redux
Redux:状态管理工具,与React没有任何关系,其他UI框架也可以使用Redux,react-redux:React插件,作用:方便在React项目中使用Redux,react-thunk:中间件,作用:支持异步action
从 源码 谈谈 redux compose
compose,英文意思 组成,构成。它的作用也是通过一系列的骚操作,实现任意的、多种的、不同的功能模块的组合,用来加强组件。很容易实现功能的组合拼装、代码复用;可以根据需要组合不同的功能;
Redux与它的中间件:redux-thunk,redux-actions,redux-promise,redux-sage
这里要讲的就是一个Redux在React中的应用问题,讲一讲Redux,react-redux,redux-thunk,redux-actions,redux-promise,redux-sage这些包的作用和他们解决的问题。
redux中间件的原理_深入理解 Redux 中间件
最近几天对 redux 的中间件进行了一番梳理,又看了 redux-saga 的文档,和 redux-thunk 和 redux-promise 的源码,结合前段时间看的redux的源码的一些思考,感觉对 redux 中间件的有了更加深刻的认识,因此总结一下
react-redux 的使用
类似于 Vue,React 中组件之间的状态管理 第三方包为:react-redux。react-redux 其实是 Redux的官方React绑定库,它能够使你的React组件从Redux store中读取数据,并且向store分发actions以更新数据。
如何使用useReducer Hook?
看到“reducer”这个词,容易让人联想到Redux,但是在本文中,不必先理解Redux才能阅读这篇文章。咱们将一起讨论“reducer”实际上是什么,以及如何利用useReducer来管理组件中的复杂状态,以及这个新钩子对Redux意味着什么?
带着问题看React-Redux源码
我在读React-Redux源码的过程中,很自然的要去网上找一些参考文章,但发现这些文章基本都没有讲的很透彻,很多时候就是平铺直叙把API挨个讲一下,而且只讲某一行代码是做什么的,却没有结合应用场景和用法解释清楚为什么这么做。
React Hooks 是不能替代 Redux 的
我的许多同事最近通过各种方式问同一类问题:“如果我们开始用 hook 后,那还有必要用 Redux 吗?”“React hook 不是让 Redux 过时了吗?那只用 Hooks 就可以做 Redux 所有能做的事了吧?”
内容以共享、参考、研究为目的,不存在任何商业目的。其版权属原作者所有,如有侵权或违规,请与小编联系!情况属实本人将予以删除!