项目中需要利用百度语音接口在Web端实现语音识别功能,采用了这样的技术方案,但实现时遇到了很多问题,发现网上大部分文章都只是在详解官方提供的example示例,对实际开发没有提供什么有价值的建议,而recorder.js是无法直接适配百度AI的语音接口的,故本篇将开发中各个细节点记录与此,欢迎指点交流。
一. 技术栈选择
需求:利用百度语音接口在Web端实现语音识别功能
技术栈:react+recorder-tool.js +recorder.js + Express + Baidu语音识别api
recorder.js项目地址:https://github.com/mattdiamond/Recorderjs
二. 前端开发细节
为recorder.js提供一个代理对象
前端的主框架采用React,在基本结构和语法上并没有太多问题,为了使用recorder.js,我们封装了一个recorder-tool.js作为代理,其实现方法较为简单,就是将官方示例中example示例中的html文件的脚本部分封装成一个单例对象作为recorder.js的代理,然后暴露一组API供上层调用,大致的结构如下:
import Recorder from './recorder-src';
//Singleton
var recorder;
//start record
function startRecord() {
recorder && recorder.record();
}
//stop record
function stopRecord(button) {
recorder && recorder.stop();
}
//....其他一些方法
export default {
init : init,
start: startRecord,
stop: stopRecord,
exportData: exportData,
sendRequest: sendRequest,
clear: clearRecord,
createDownloadLink : createDownloadLink
}解除exportWAV方法的回调地狱
官方示例中输出wav编码格式的数据这个动作是通过webworker来完成的,也就是说二进制数据处理的开始和结束时间点是通过事件来触发的,recorder.exportWAV( )接收一个回调函数作为入参,在得到wav格式的数据后会执行传入的回调函数,如果要在react中实现,就需要写成:
//record-page.js
...
//处理录音-事件监听
proce***ecord(){
RecorderTools.exportData(function(blob){
var wav = preProcessData(blob);
//发送请求
axios.post({...})
.then(function(response){
handle(response);
})
});
}
...你或许已经发现了这个【回调地狱】的现象,深度的嵌套会让逻辑变的复杂且代码高度耦合,想把一些方法从react中剥离出去非常困难,我们希望使用一些其他的方式来转换代码的控制权,而不是把一大堆后续的逻辑传进exportData( )方法。
方法一:使用HTML自定义事件
我们在一个存在的dom元素上添加一个自定义事件recorder.export的监听器,并在传入recorder.exportWAV( )方法的回调函数中,手动初始化触发一个自定义事件(暂不考虑兼容性问题),并把recorder.js导出的数据挂在这个event对象上,然后在指定元素上派发这个事件:
//export data
function exportData() {
recorder && recorder.exportWAV(function (blob) {
//init event
var exportDone = document.createEvent('HTMLEvents');
exportDone.initEvent('recorder.export', true, true);
//add payload
exportDone.data = blob;
//dispatch
document.getElementById('panel').dispatchEvent(exportDone);
});
}这样我们后续的处理逻辑就可以用常规的方式在React组件中继续编写后续的业务逻辑,这样就实现了基本的职责分离和代码分离。
方法二:监听WebWorker
recorder.js中使用DOM0级事件模型来与webworker通讯,为了不覆盖原功能,我们可以通过DOM2事件模型在recorder实例上绑定额外的监听器:
recorder.worker.addEventListener('message',function(event){
//event.data中就包含了转换后的WAV数据
processData(event.data);
...
})这样我们就可以在自己的逻辑代码或二次封装的代码中实现对转码动作的监听。
方法三:Promise化
使用Promise来实现异步的调用,将音频处理的代码剥离出去,最终的调用方式为:
RecorderTools.exportData().then(data){
//继续在React组件文件中编写其他逻辑或调用方法
}参考代码如下:
//RecorderTools.js中的方法定义
function exportData(){
return new Promise(function(resolve, reject){
recorder && recorder.exportWAV(function(blob){
resolve(blob);
})
});
}回调,事件监听,Promise都是javascript中重要的异步模式,根据个人喜好和实际场景选择使用即可。
如何提交Blob对象
通过recorder.js的官方示例可以看到,如果不将录音输出为本地wav格式的文件,我们得到的是一个Blob对象,Blob对象需要使用form表单的方式进行提交,具体方法如下(使用axios发送http请求):
var formData = new FormData();
formData.set('recorder.wav',blob);//blob即为要发送的数据
axios({
url:'http://localhost:8927/transmit',
method : 'POST',
headers:{
'Content-Type': 'multipart/form-data'//此处也可以赋值为false
},
data:formData
});三. Recorder.js的功能扩展
百度AI语音识别接口接收的语音文件需要满足如下的要求:
- pcm格式或wav格式文件的二进制数据经过base64转换后的编码
- 16000Hz采样率
- 16bit位深
- 单声道
要利用recorder.js实现上述需求,需要对源码进行一些功能扩展。编码转换可以在服务端进行,而recorder.js中的floatTo16BitPCM( )方法看名字应该是为了满足16bit位深这个条件的,那么我们只需要考虑单声道和16000采样率这两个条件了。
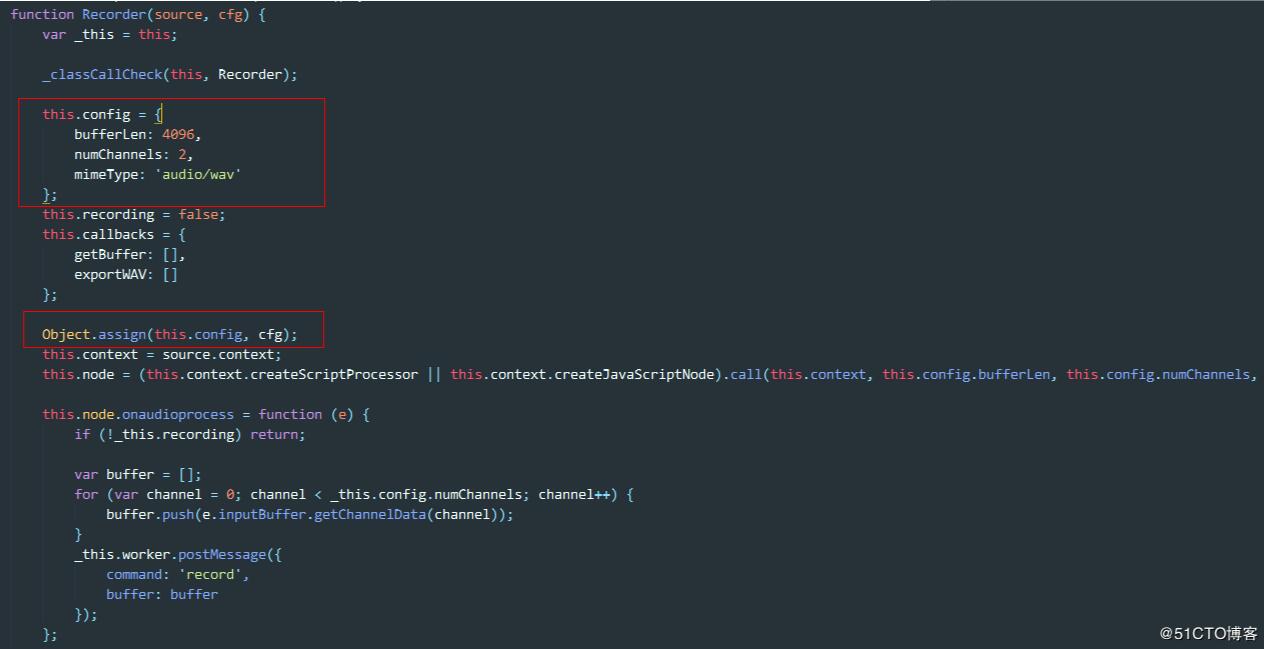
源码中Recorder构造函数是可以接受参数的,而这个参数会被合入实例的config属性,其中numChannles就是声道数,所以我们只需要在实例化是传入自定义的声道数目即可:
new Recorder({
numChannels:1//单声道
})再来看16000采样率这个条件,查看源码可以知道,源码中对于sampleRate的使用,一律使用了音频流数据源上下文的sampleRate,也就是对应着电脑声卡的采样率(48000Hz或44100Hz),那如何得到16000Hz采样率的数据呢?比如一个48000Hz采样率的声卡采集的信号点,1秒采集了48000次,那么这48000个数据要变成16000个数据,最简单的办法就是每4个点取1个然后组成新的数据,也就是说实际上声音采集设备传过来的采样率是固定的,我们需要多少的采样率,只需要自己拿一个比例系数去换算一下,然后丢弃掉一部分数据点(当然也可以求平均值)就可以了,封装后的调用方式为:
new Recorder({
numChannels:1,
sampleRate:16000
});那么在源码中需要做一些功能的扩展,关键的部分在下面这段代码:
//recorder.js部分源码
function exportWAV(type) {
var buffers = [];
for (var channel = 0; channel < numChannels; channel++) {
buffers.push(mergeBuffers(recBuffers[channel], recLength));
}
var interleaved = undefined;
if (numChannels === 2) {
interleaved = interleave(buffers[0], buffers[1]);
} else {
interleaved = buffers[0];
//此处是重点,可以看到对于单声道的情况是没有进行处理的,那么仿照双声道的处理方式来添加采样函数,此处改为interleaved = extractSingleChannel(buffers[0]);
}
var dataview = encodeWAV(interleaved);
var audioBlob = new Blob([dataview], { type: type });
self.postMessage({ command: 'exportWAV', data: audioBlob });
}extractSingleChannel( )的具体实现参考interleave( )方法
/**
*sampleStep是系统的context.sampleRate/自定义sampleRate后取整的结果,这个方法实现了对单声道的*采样数据处理。
*/
function extractSingleChannel(input) {
//如果此处不按比例缩短,实际输出的文件会包含sampleStep倍长度的空录音
var length = Math.ceil(input.length / sampleStep);
var result = new Float32Array(length);
var index = 0,
inputIndex = 0;
while (index < length) {
//此处是处理关键,算法就是输入的数据点每隔sampleStep距离取一个点放入result
result[index++] = input[inputIndex];
inputIndex += sampleStep;
}
return result;
}这样处理后exportWAV( )方法输出的Blob对象中存放的数据就满足了百度语音的识别要求。
四. 服务端开发细节
在服务端我们使用Express框架来部署一个消息中转服务,这里涉及的知识点相对较少,可以使用百度AI的nodejs-sdk来实现,也可以自行封装,权限验证的方法几乎都是通用的,按照官方文档来做就可以了。
通过multipart/form-data方式提交的表单无法直接通过req.body或req.params进行处理,这里使用官方推荐的Multer中间件来处理,此处较为简单,直接附上笔者的参考代码:
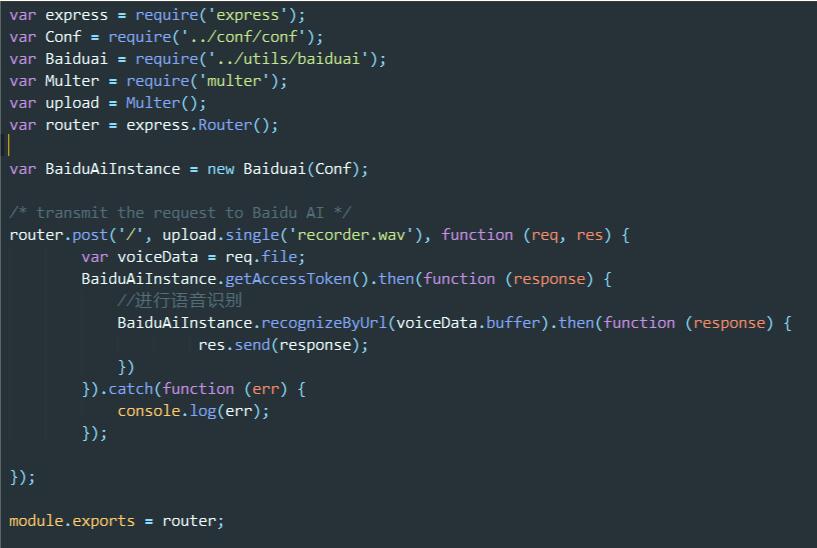
此处有一点需要注意的是:在实例化Multer时,传参和不传参时得到的转换对象是不一样的,如果涉及到相关场景可以直接在控制台打印出来确保使用了正确的属性。
原文出处:https://www.cnblogs.com/dashnowords/p/9557355.html
一些常用的语音特征提取算法
语言是一种复杂的自然习得的人类运动能力。成人的特点是通过大约100块肌肉的协调运动,每秒发出14种不同的声音。说话人识别是指软件或硬件接收语音信号,识别语音信号中出现的说话人,然后识别说话人的能力
Chrome浏览器语音自动播放功能
Chrome浏览器为了屏蔽带声音的骚扰广告,从66版本后不再允许自动播放语音,我做的项目需要实时语音提示报警信息,网上搜索了好久都说不再支持自动播放,知道碰到一个大神提供建议设置Chrome浏览器允许声音自动播放:
Js文字转语音_SpeechSynthesisUtterance语音合成使用
在做项目的过程中,遇到场景是客户要求播放语音的场景,这里需要Js来实现文字转语音播放的功能,SpeechSynthesisUtterance是HTML5中新增的API
内容以共享、参考、研究为目的,不存在任何商业目的。其版权属原作者所有,如有侵权或违规,请与小编联系!情况属实本人将予以删除!